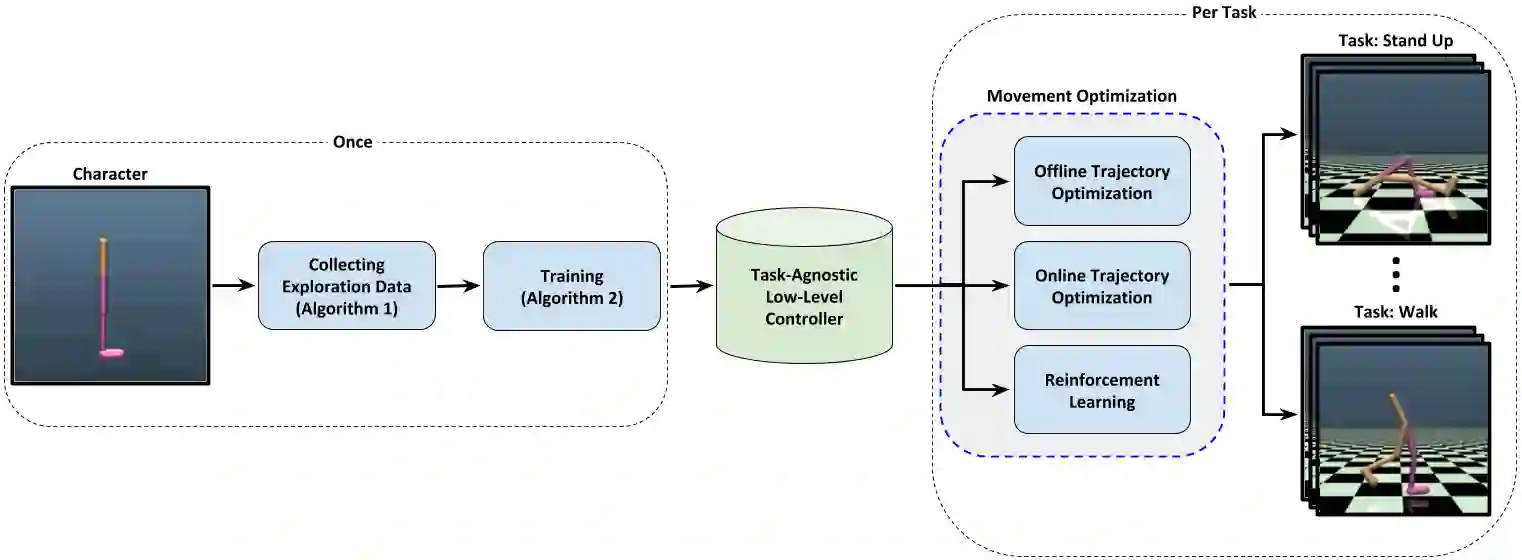
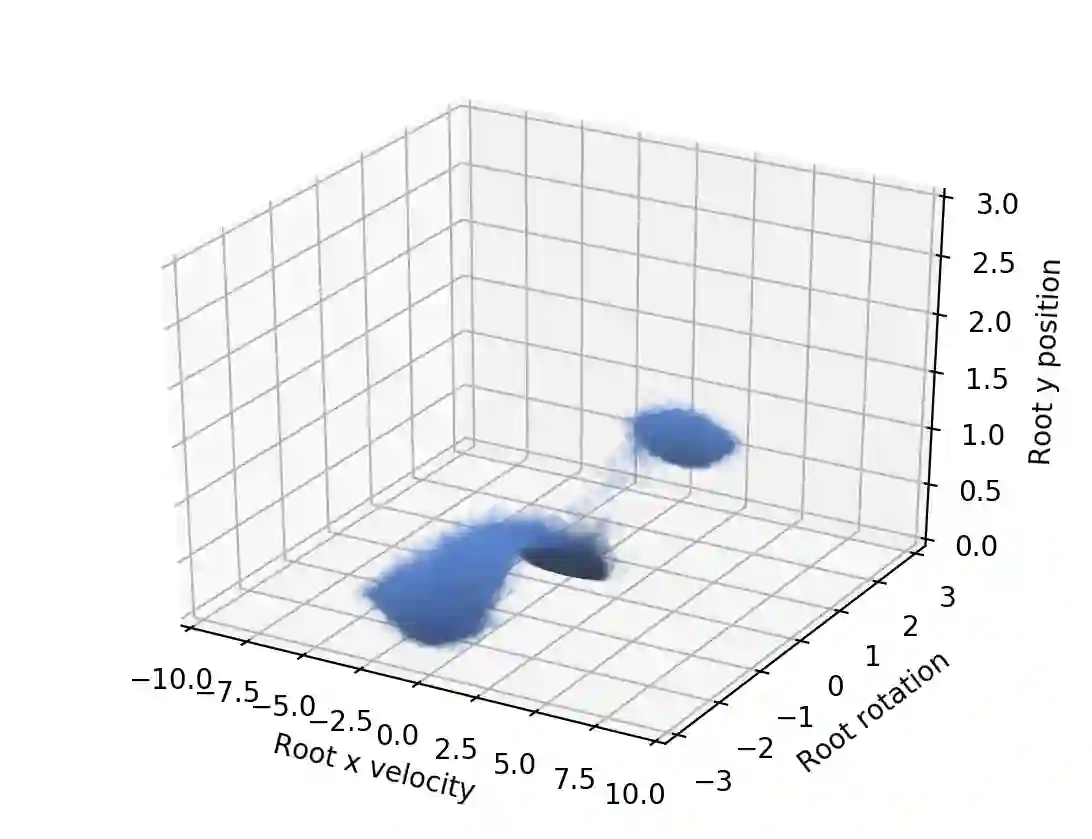
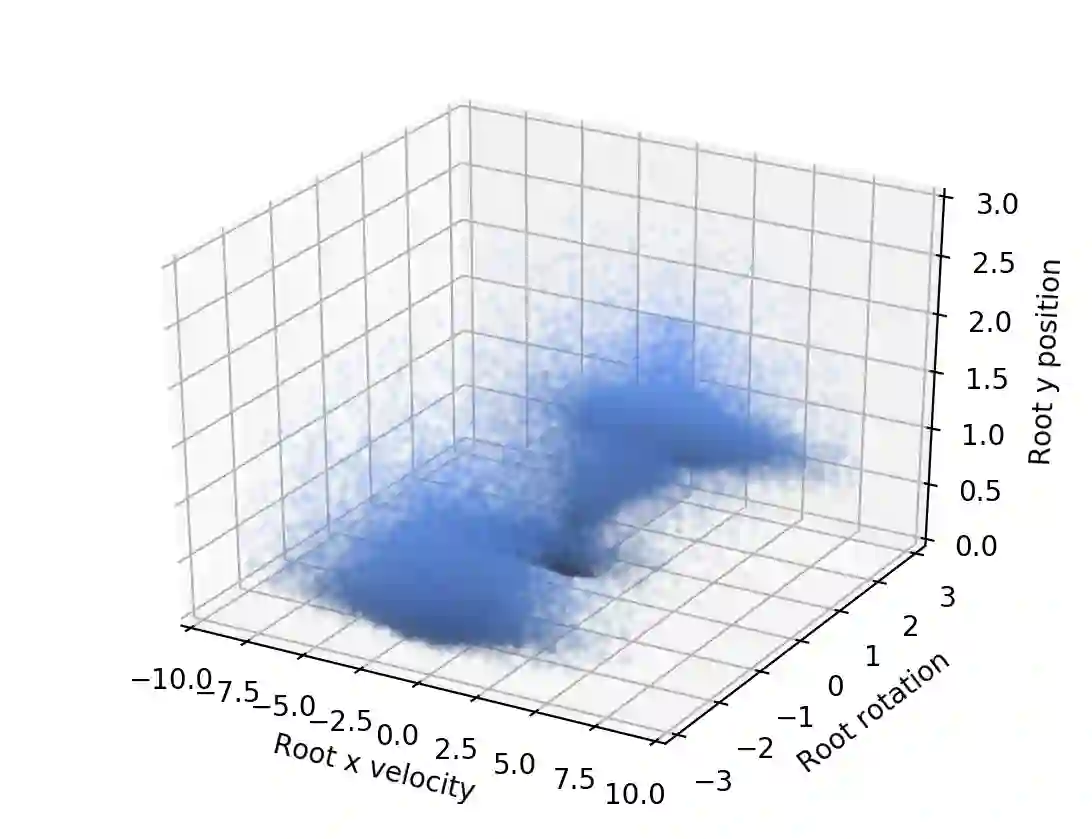
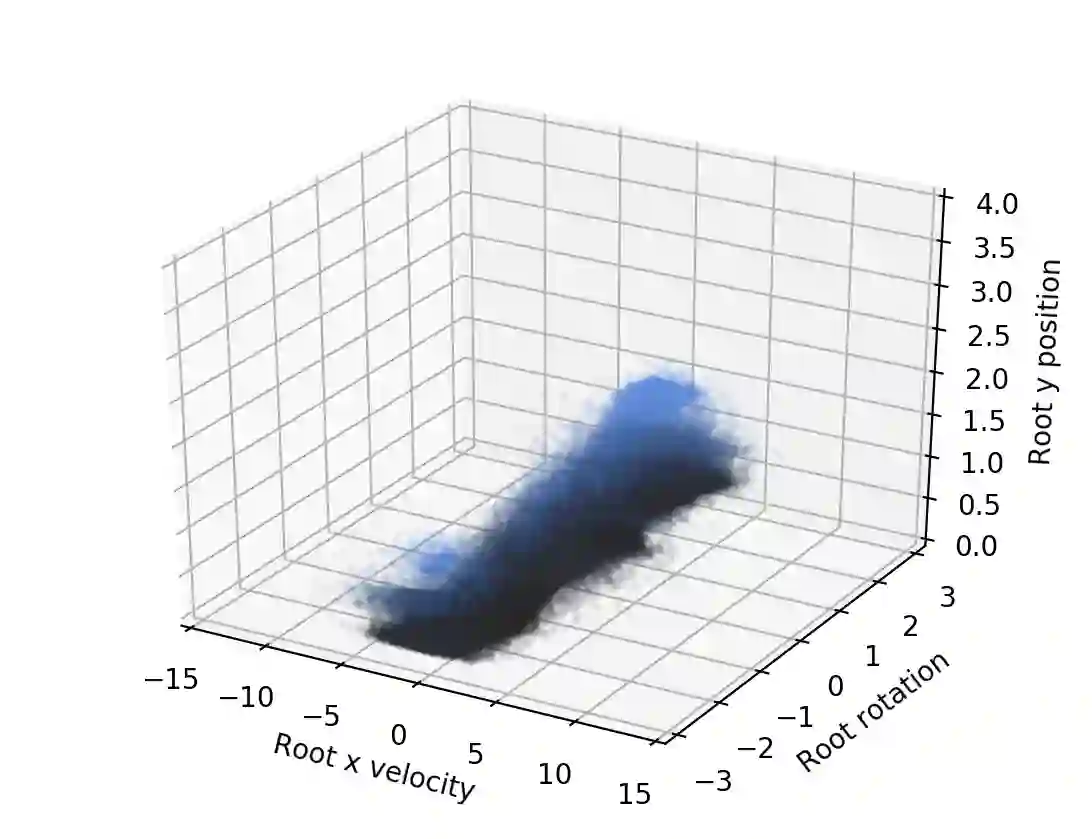
We propose a novel method for exploring the dynamics of physically based animated characters, and learning a task-agnostic action space that makes movement optimization easier. Like several previous papers, we parameterize actions as target states, and learn a short-horizon goal-conditioned low-level control policy that drives the agent's state towards the targets. Our novel contribution is that with our exploration data, we are able to learn the low-level policy in a generic manner and without any reference movement data. Trained once for each agent or simulation environment, the policy improves the efficiency of optimizing both trajectories and high-level policies across multiple tasks and optimization algorithms. We also contribute novel visualizations that show how using target states as actions makes optimized trajectories more robust to disturbances; this manifests as wider optima that are easy to find. Due to its simplicity and generality, our proposed approach should provide a building block that can improve a large variety of movement optimization methods and applications.
翻译:我们提出了一个探索基于物理动画字符动态的新方法,并学习一个使运动优化更加容易的任务不可知的动作空间。和前几份论文一样,我们将行动参数化为目标状态,并学习一个驱动代理人状态向目标状态的短等离子目标低水平控制政策。我们的新贡献是,通过我们的探索数据,我们能够以通用的方式学习低层次政策,而没有任何参考移动数据。对每个代理商或模拟环境进行了一次培训,该政策提高了优化多任务和优化算法之间轨道和高层次政策的效率。我们还贡献了新颖的可视化,显示将目标状态作为行动如何使优化的轨迹对扰动更加强大;这表现为更容易找到的更宽广的opima。由于它既简单又笼统,我们提议的方法应该提供一个构件,可以改进多种运动优化方法和应用。