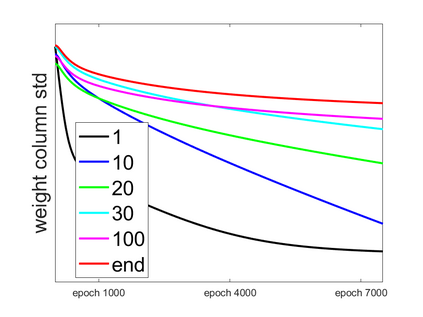
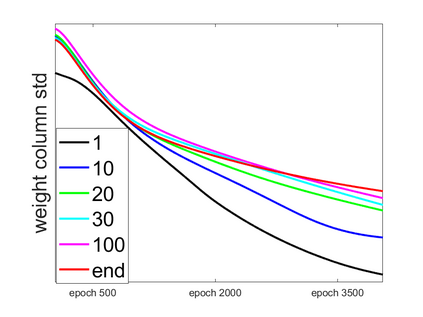
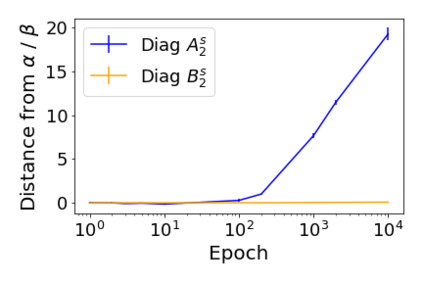
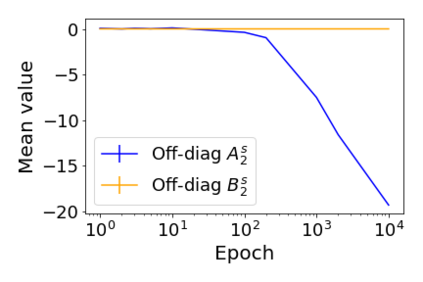
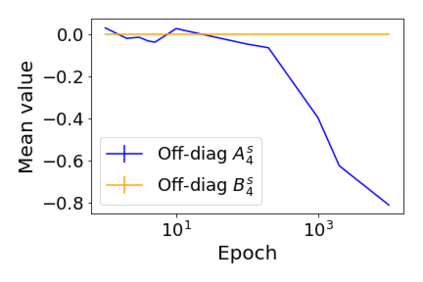
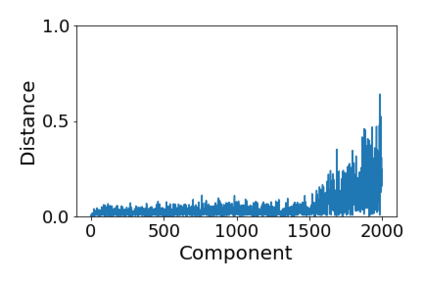
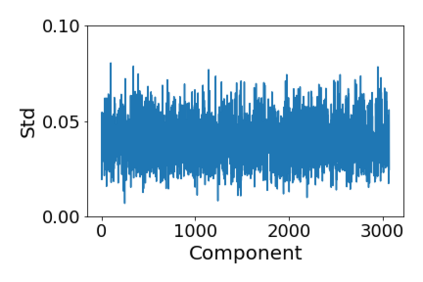
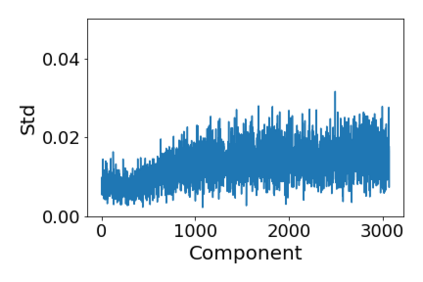
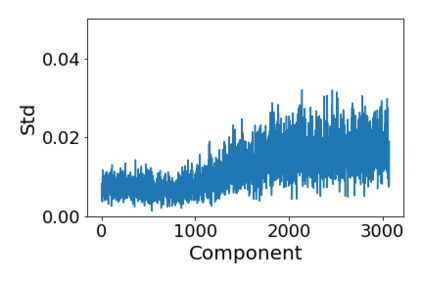
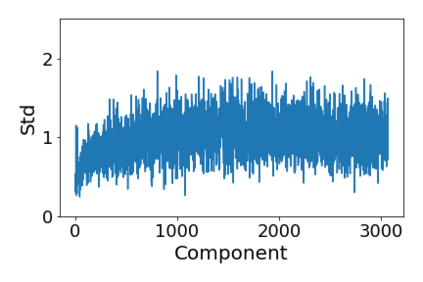
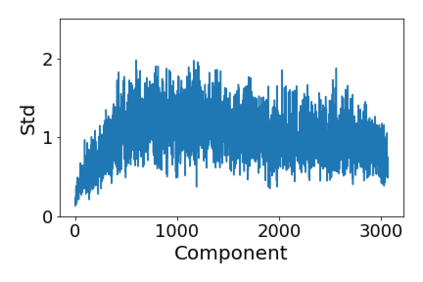
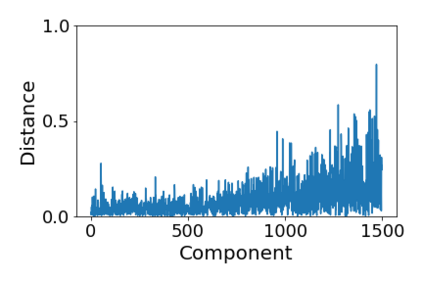
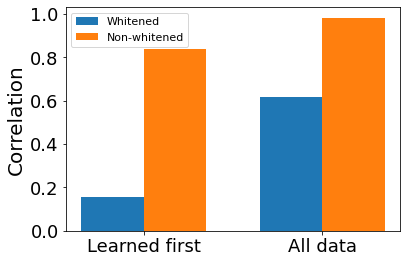
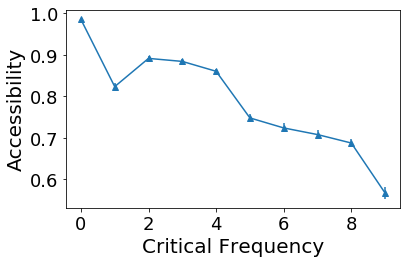
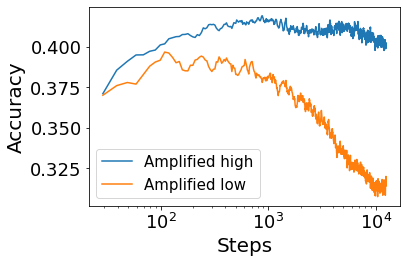
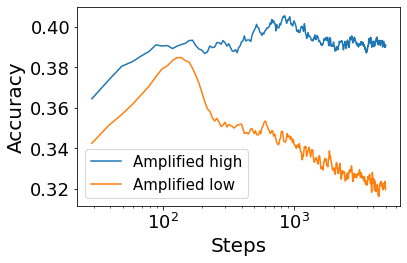
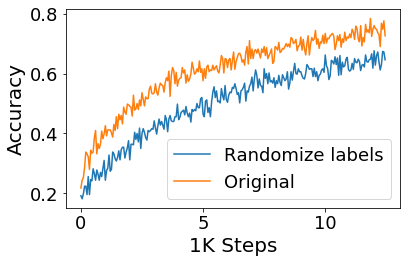
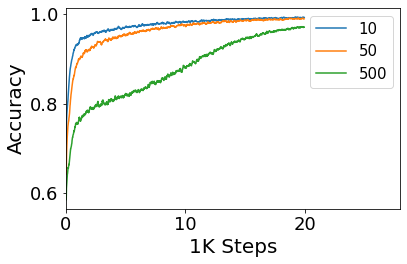
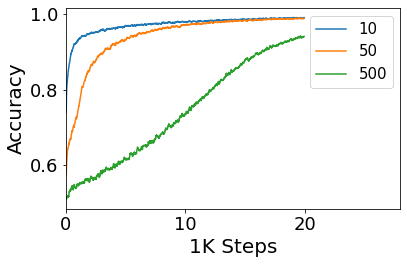
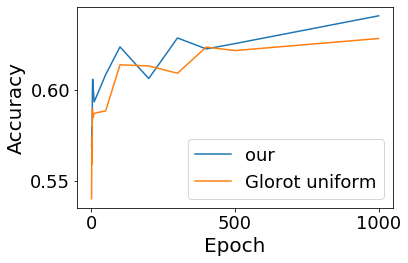
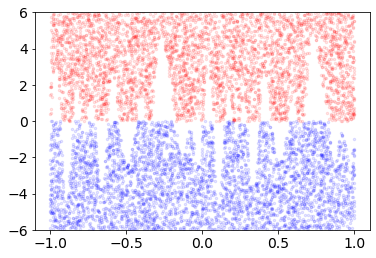
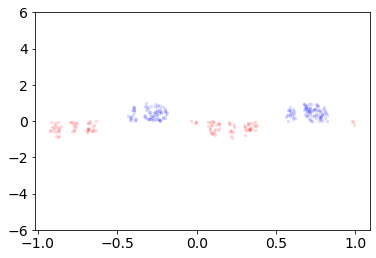
Convolutional Neural networks of different architectures seem to learn to classify images in the same order. To understand this phenomenon, we revisit the over-parametrized deep linear network model. Our analysis of this model's learning dynamics reveals that the convergence rate of its parameters is exponentially faster along directions corresponding to the larger principal components of the data, at a rate governed by the singular values. We term this convergence pattern the Principal Components bias (PC-bias). We show how the PC-bias streamlines the order of learning of both linear and non-linear networks, more prominently in earlier stages of learning. We then compare our results to the spectral bias, showing that both biases can be seen independently, and affect the order of learning in different ways. Finally, we discuss how the PC-bias can explain several phenomena, including the benefits of prevalent initialization schemes, how early stopping may be related to PCA, and why deep networks converge more slowly when given random labels.
翻译:不同结构的连锁神经网络似乎学会按同一顺序对图像进行分类。 为了理解这一现象, 我们重新审视了过度平衡的深线网络模型。 我们对这一模型的学习动态分析显示, 其参数的趋同率在与数据中较大主要组成部分相对应的方向上, 以单一值所支配的速率, 指数指数指数指数更快。 我们将这种趋同模式称为主构偏向( PC- bias) 。 我们显示了PC- 点如何简化线性和非线性网络的学习顺序, 在早期学习阶段更为突出。 然后我们将我们的结果与光谱偏差进行比较, 表明两种偏差都可以独立地看到, 并且以不同的方式影响学习顺序。 最后, 我们讨论PC- 点如何解释几种现象, 包括流行的初始化计划的好处, 早期停止可能与五氯苯有关, 以及为什么在给定随机标签时深网络会比较慢。