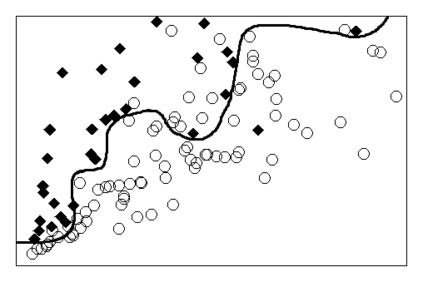
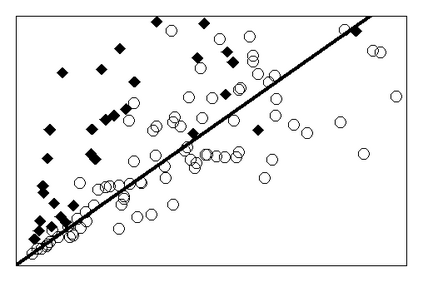
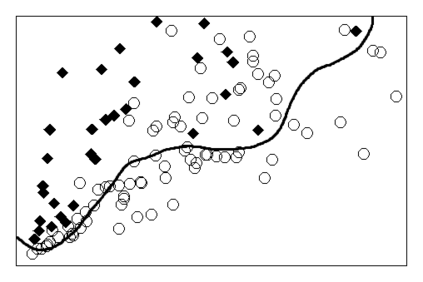
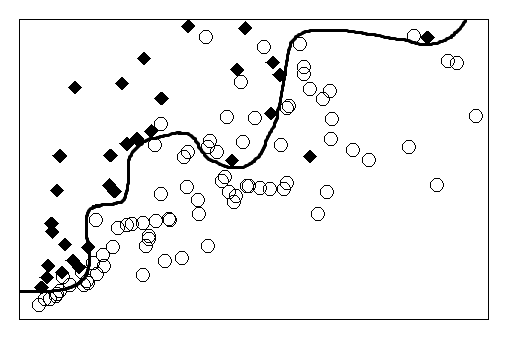
Machine learning operates at the intersection of statistics and computer science. This raises the question as to its underlying methodology. While much emphasis has been put on the close link between the process of learning from data and induction, the falsificationist component of machine learning has received minor attention. In this paper, we argue that the idea of falsification is central to the methodology of machine learning. It is commonly thought that machine learning algorithms infer general prediction rules from past observations. This is akin to a statistical procedure by which estimates are obtained from a sample of data. But machine learning algorithms can also be described as choosing one prediction rule from an entire class of functions. In particular, the algorithm that determines the weights of an artificial neural network operates by empirical risk minimization and rejects prediction rules that lack empirical adequacy. It also exhibits a behavior of implicit regularization that pushes hypothesis choice toward simpler prediction rules. We argue that taking both aspects together gives rise to a falsificationist account of artificial neural networks.
翻译:机器学习在统计和计算机科学的交汇处运作。这引起了一个有关其基本方法的问题。虽然已经非常强调从数据学习过程与诱导过程之间的密切联系,但机器学习的伪造学成分却受到很少重视。在本文中,我们争辩说,伪造思想是机器学习方法的核心。人们通常认为,机器学习算法从过去的观察中推导出一般预测规则。这类似于从抽样数据中获得估计数的统计程序。但是机器学习算法也可以被描述为从整个功能类别中选择一种预测规则。特别是,通过实验风险最小化确定人造神经网络重量的算法,并拒绝缺乏经验充分的预测规则。它也显示出一种隐含的正规化行为,将假设选择推向更简单的预测规则。我们争辩说,将这两个方面结合起来,就可以产生人工神经网络的伪造学学解释。