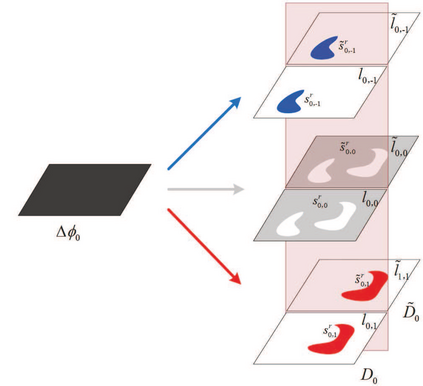
Recently, various view synthesis distortion estimation models have been studied to better serve for 3-D video coding. However, they can hardly model the relationship quantitatively among different levels of depth changes, texture degeneration, and the view synthesis distortion (VSD), which is crucial for rate-distortion optimization and rate allocation. In this paper, an auto-weighted layer representation based view synthesis distortion estimation model is developed. Firstly, the sub-VSD (S-VSD) is defined according to the level of depth changes and their associated texture degeneration. After that, a set of theoretical derivations demonstrate that the VSD can be approximately decomposed into the S-VSDs multiplied by their associated weights. To obtain the S-VSDs, a layer-based representation of S-VSD is developed, where all the pixels with the same level of depth changes are represented with a layer to enable efficient S-VSD calculation at the layer level. Meanwhile, a nonlinear mapping function is learnt to accurately represent the relationship between the VSD and S-VSDs, automatically providing weights for S-VSDs during the VSD estimation. To learn such function, a dataset of VSD and its associated S-VSDs are built. Experimental results show that the VSD can be accurately estimated with the weights learnt by the nonlinear mapping function once its associated S-VSDs are available. The proposed method outperforms the relevant state-of-the-art methods in both accuracy and efficiency. The dataset and source code of the proposed method will be available at https://github.com/jianjin008/.
翻译:最近,对各种观点综合扭曲估计模型进行了研究,以更好地为3D视频编码服务。然而,这些模型很难从数量上模拟不同深度变化水平、质谱脱解和视图合成扭曲(VSD)之间的关系,这对率扭曲优化和比例分配至关重要。在本文件中,开发了基于自动加权层代表的视图综合扭曲估计模型。首先,根据深度变化程度及其相关的纹理脱产,对子VSD(S-VSD)进行了定义。随后,一套理论衍生数据表明,VSD可以以相关重量乘以S-VSD。要获得S-VSD,SVSD基于层代表S-VSD的表示方式,所有具有相同深度变化水平的像素代表一个层,以便能够在层一级进行高效的S-VSD计算。同时,一个非线性绘图功能可以准确反映源与SD的关系,为S-VSD提供SD的自动加权,在VSD的模型中,SSSD的精确值将显示SD的SD方法,在VSD的精确性分析中,在VSD的SD中,在SD中,在SD中,在SD中,在SD中,在SDSD中,在SD中,可以进行相应的,在SDSD中,在SDSD中,在SD的精确的计算中,在SD中,在SD中,在SD中,在SD中,可以学习。