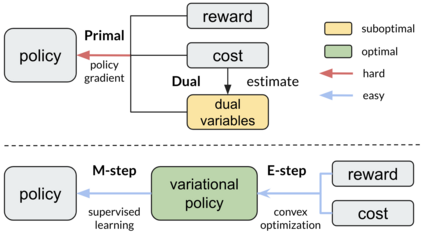
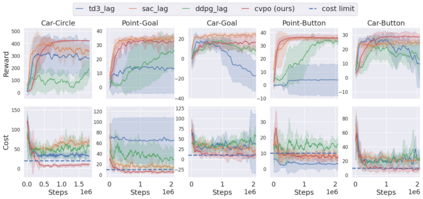
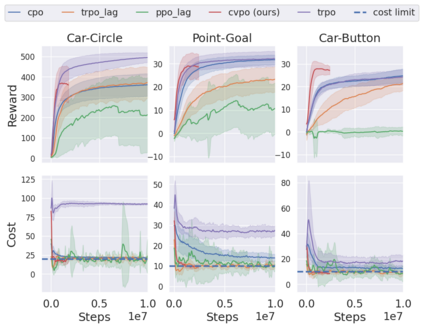
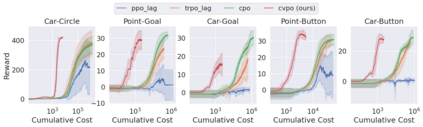
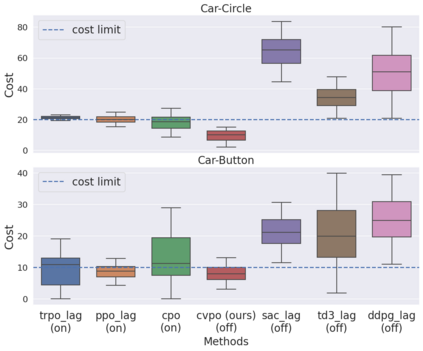
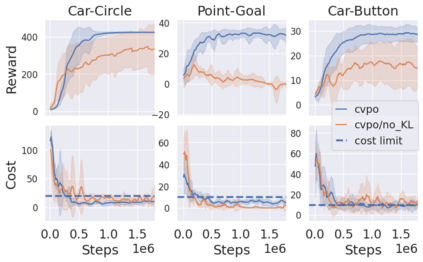
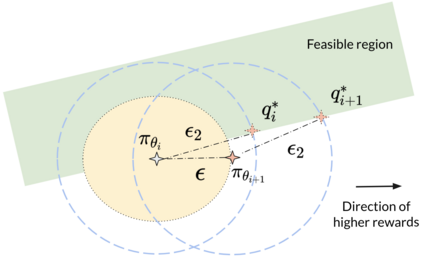
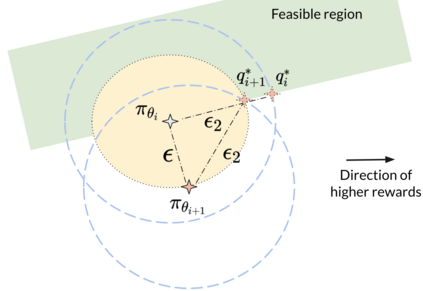
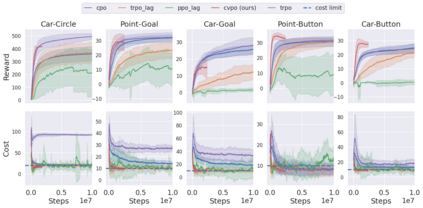
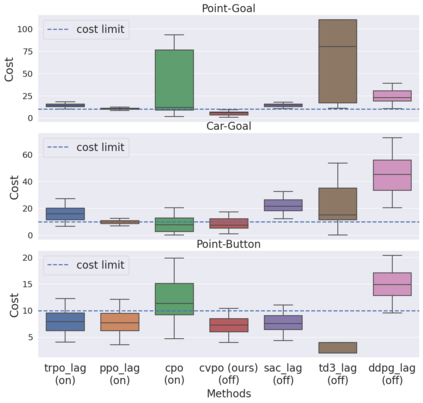
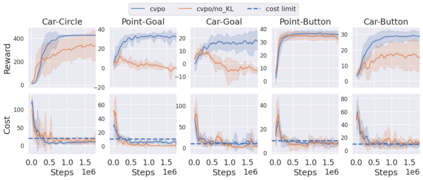
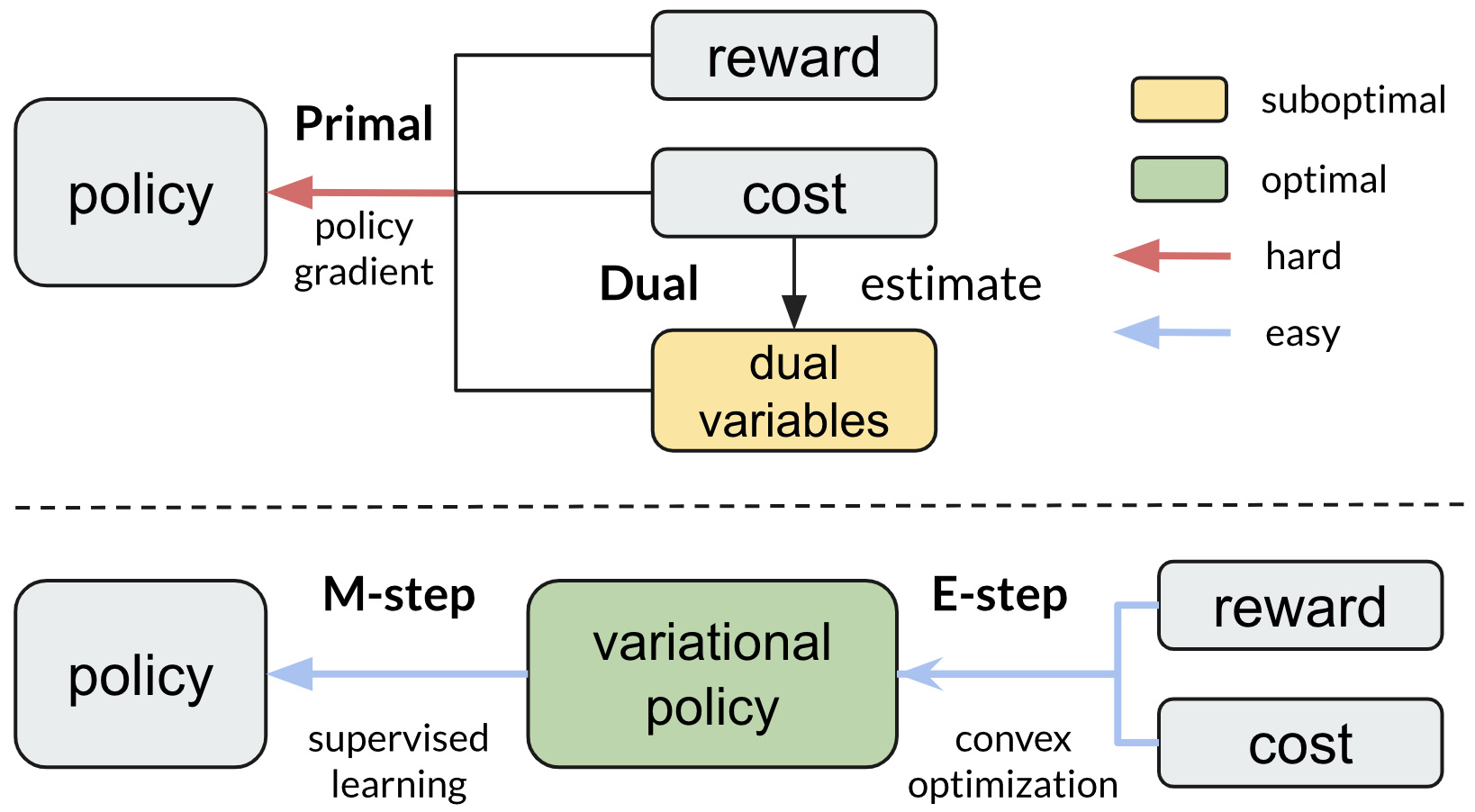
Safe reinforcement learning (RL) aims to learn policies that satisfy certain constraints before deploying them to safety-critical applications. Previous primal-dual style approaches suffer from instability issues and lack optimality guarantees. This paper overcomes the issues from the perspective of probabilistic inference. We introduce a novel Expectation-Maximization approach to naturally incorporate constraints during the policy learning: 1) a provable optimal non-parametric variational distribution could be computed in closed form after a convex optimization (E-step); 2) the policy parameter is improved within the trust region based on the optimal variational distribution (M-step). The proposed algorithm decomposes the safe RL problem into a convex optimization phase and a supervised learning phase, which yields a more stable training performance. A wide range of experiments on continuous robotic tasks shows that the proposed method achieves significantly better constraint satisfaction performance and better sample efficiency than baselines. The code is available at https://github.com/liuzuxin/cvpo-safe-rl.
翻译:安全强化学习(RL)旨在学习满足某些限制的政策,然后将其部署到安全关键应用中。以前的初等风格方法存在不稳定问题,缺乏最佳的保障。本文从概率推论的角度克服了问题。我们引入了新的期望-最大化方法,自然地将政策学习过程中的制约因素纳入其中:1) 在调控优化后,可以以封闭的形式计算出一个可证实的最佳非参数差异分布;2) 政策参数在信任区域内根据最佳的变异分布(M-step)得到改进。提议的算法将安全RL问题分解成一个凝固优化阶段和一个有监督的学习阶段,从而产生更稳定的培训绩效。关于连续机器人任务的广泛实验表明,拟议的方法比基线大大改进了满意度和样本效率。该代码可在https://github.com/liuzuxin/cvpo-safe-rl查阅。