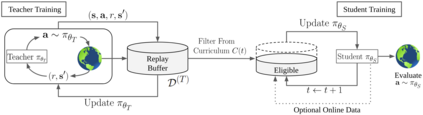
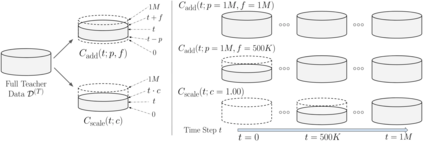
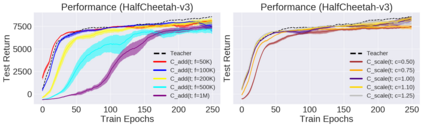
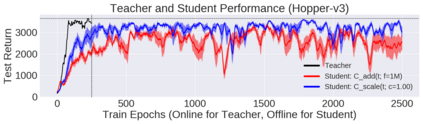
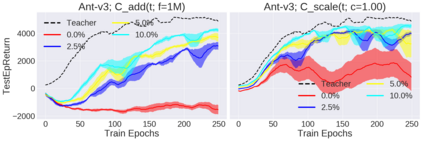
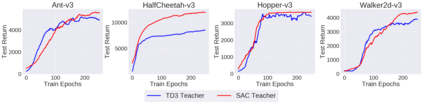
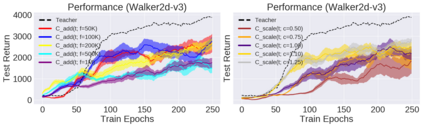
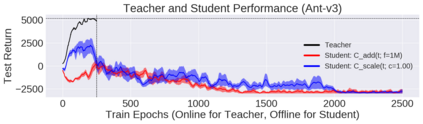
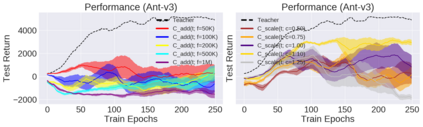
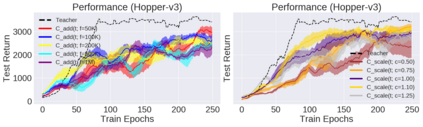
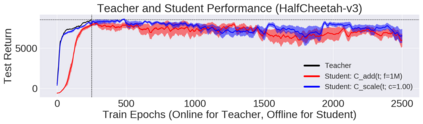
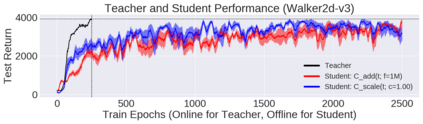
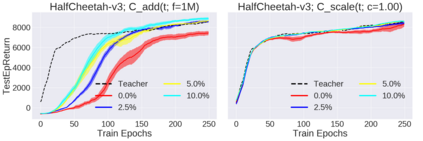
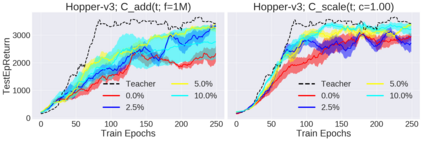
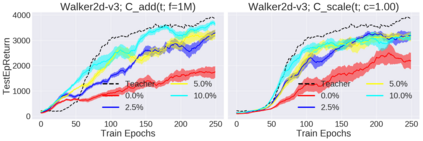
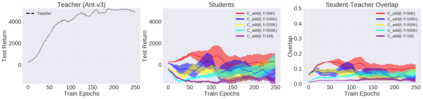
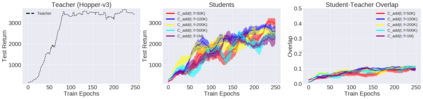
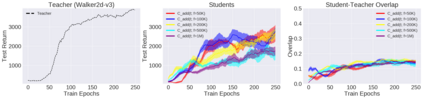
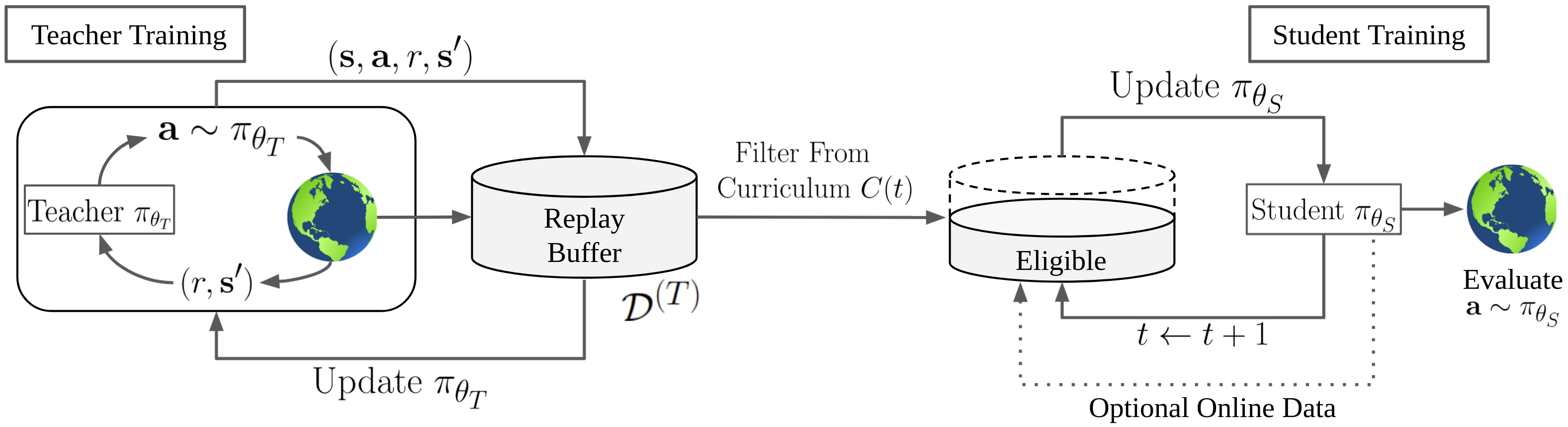
Deep reinforcement learning (RL) has shown great empirical successes, but suffers from brittleness and sample inefficiency. A potential remedy is to use a previously-trained policy as a source of supervision. In this work, we refer to these policies as teachers and study how to transfer their expertise to new student policies by focusing on data usage. We propose a framework, Data CUrriculum for Reinforcement learning (DCUR), which first trains teachers using online deep RL, and stores the logged environment interaction history. Then, students learn by running either offline RL or by using teacher data in combination with a small amount of self-generated data. DCUR's central idea involves defining a class of data curricula which, as a function of training time, limits the student to sampling from a fixed subset of the full teacher data. We test teachers and students using state-of-the-art deep RL algorithms across a variety of data curricula. Results suggest that the choice of data curricula significantly impacts student learning, and that it is beneficial to limit the data during early training stages while gradually letting the data availability grow over time. We identify when the student can learn offline and match teacher performance without relying on specialized offline RL algorithms. Furthermore, we show that collecting a small fraction of online data provides complementary benefits with the data curriculum. Supplementary material is available at https://tinyurl.com/teach-dcur.
翻译:深入强化学习(RL)已经展示了巨大的实证成功,但是也存在不完善和抽样效率低下的问题。 潜在的补救办法是使用以前训练过的政策作为监督的来源。 在这项工作中,我们把这些政策称为教师,研究如何通过注重数据使用来将自己的专长转换为新的学生政策。 我们提出了一个框架,即“强化学习的数据曲线”(DCUR),首先用在线深度RL来培训教师,然后储存记录的环境互动历史。然后,学生通过运行离线的RL或使用教师数据与少量自产数据相结合来学习。DCUR的中心想法是确定一组数据课程,作为培训时间的函数,限制学生从固定的教师数据分组中取样。我们建议建立一个框架,即“强化学习的数据曲线仪”(DDCUR),首先利用在线深层RL算法对教师进行测试,结果显示,数据课程的选择对学生学习有重大影响,在早期培训阶段限制数据,同时逐渐使数据供应量与少量自产数据一同增长。我们确定,当学生能够学习离线/在线补充教师数据时,我们可以通过在线数据库提供部分数据。