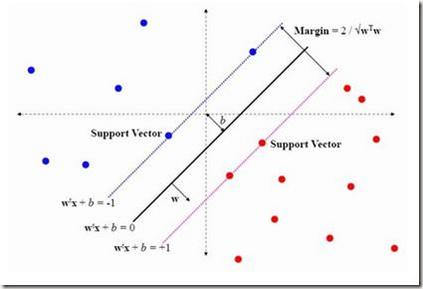
Selecting radiology examination protocol is a repetitive, and time-consuming process. In this paper, we present a deep learning approach to automatically assign protocols to computer tomography examinations, by pre-training a domain-specific BERT model ($BERT_{rad}$). To handle the high data imbalance across exam protocols, we used a knowledge distillation approach that up-sampled the minority classes through data augmentation. We compared classification performance of the described approach with the statistical n-gram models using Support Vector Machine (SVM) and Random Forest (RF) classifiers, as well as the Google's $BERT_{base}$ model. SVM and RF achieved macro-averaged F1 scores of 0.45 and 0.6 while $BERT_{base}$ and $BERT_{rad}$ achieved 0.61 and 0.63. Knowledge distillation improved overall performance on the minority classes, achieving a F1 score of 0.66.
翻译:选择放射检查程序是一个重复和耗时的过程。 在本文中,我们提出了一个深层次的学习方法,通过对特定领域的BERT模型(BERT+ ⁇ rad}$)进行预培训,自动为计算机摄影检查指定规程。为了处理各考试程序之间数据高度不平衡的问题,我们采用了知识蒸馏方法,通过数据扩增对少数群体类别进行取样。我们用支持矢量机(SVM)和随机森林(Random Forest)分类器以及谷歌的$BERT ⁇ base}模型,将所述方法的分类性能与统计ngram模型进行比较。SVM和RF实现了0.45和0.6的宏观平均F1分,而$BERT ⁇ bard}和$BERT ⁇ rad}则实现了0.61和0.63美元。我们将所述方法的分类性能与统计ngram模型进行比较,使少数群体类别的总体性能得到改善,达到0.66的F1分。