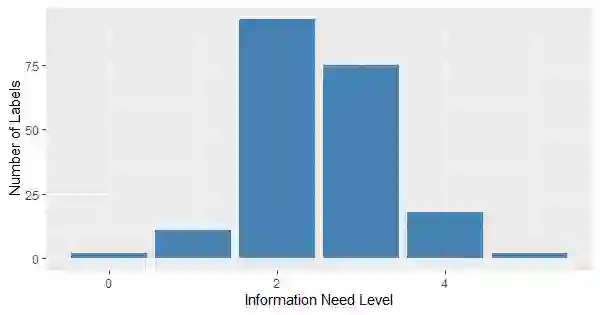
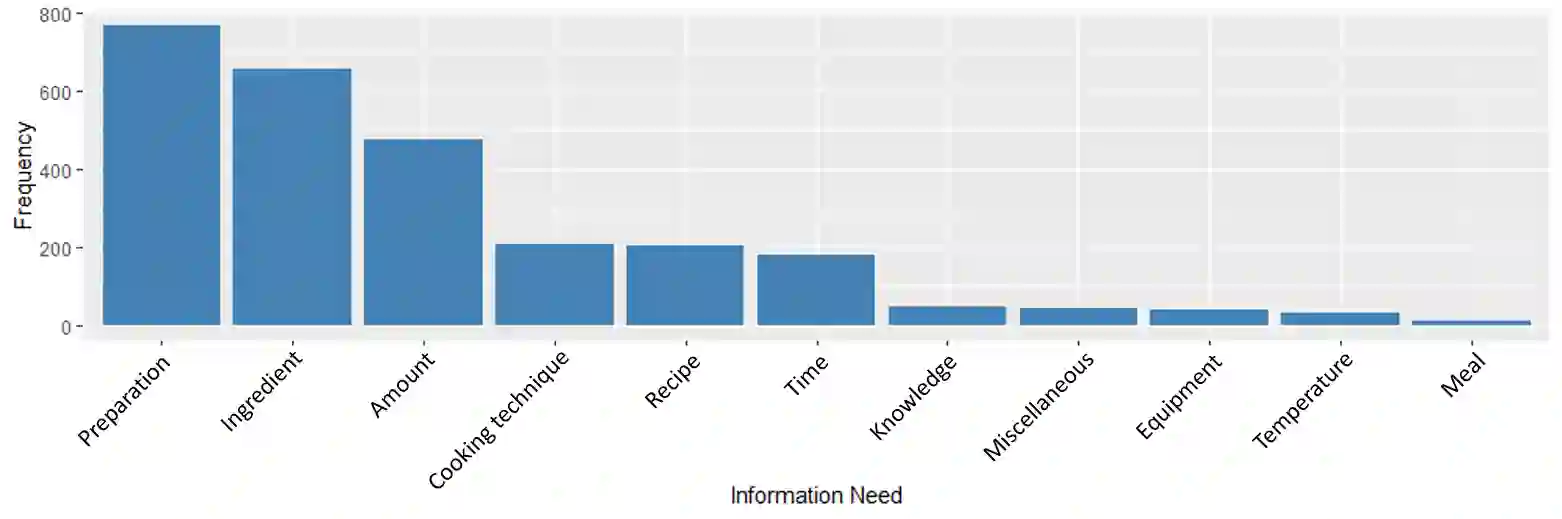
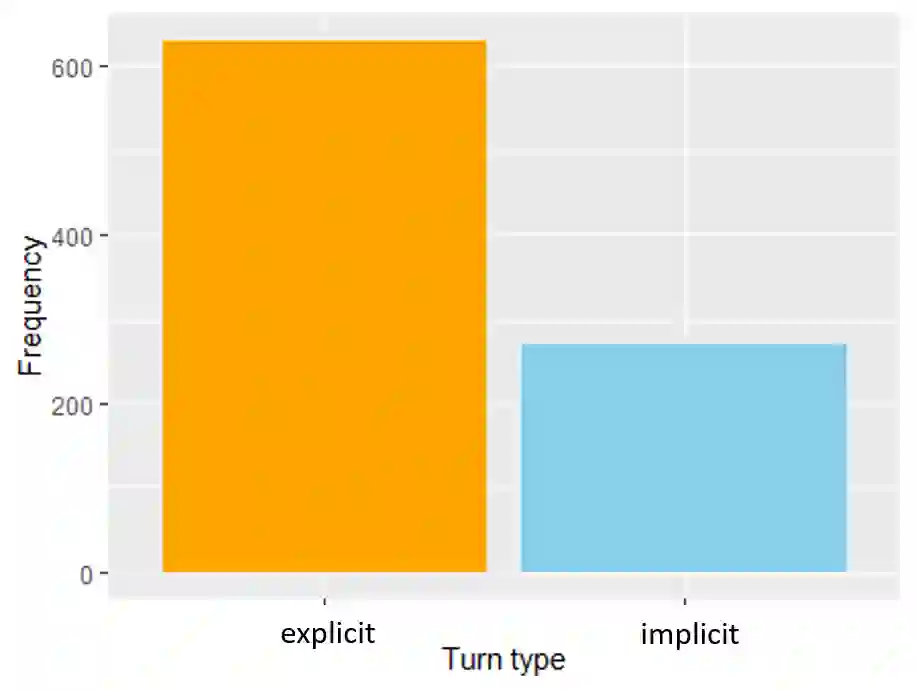
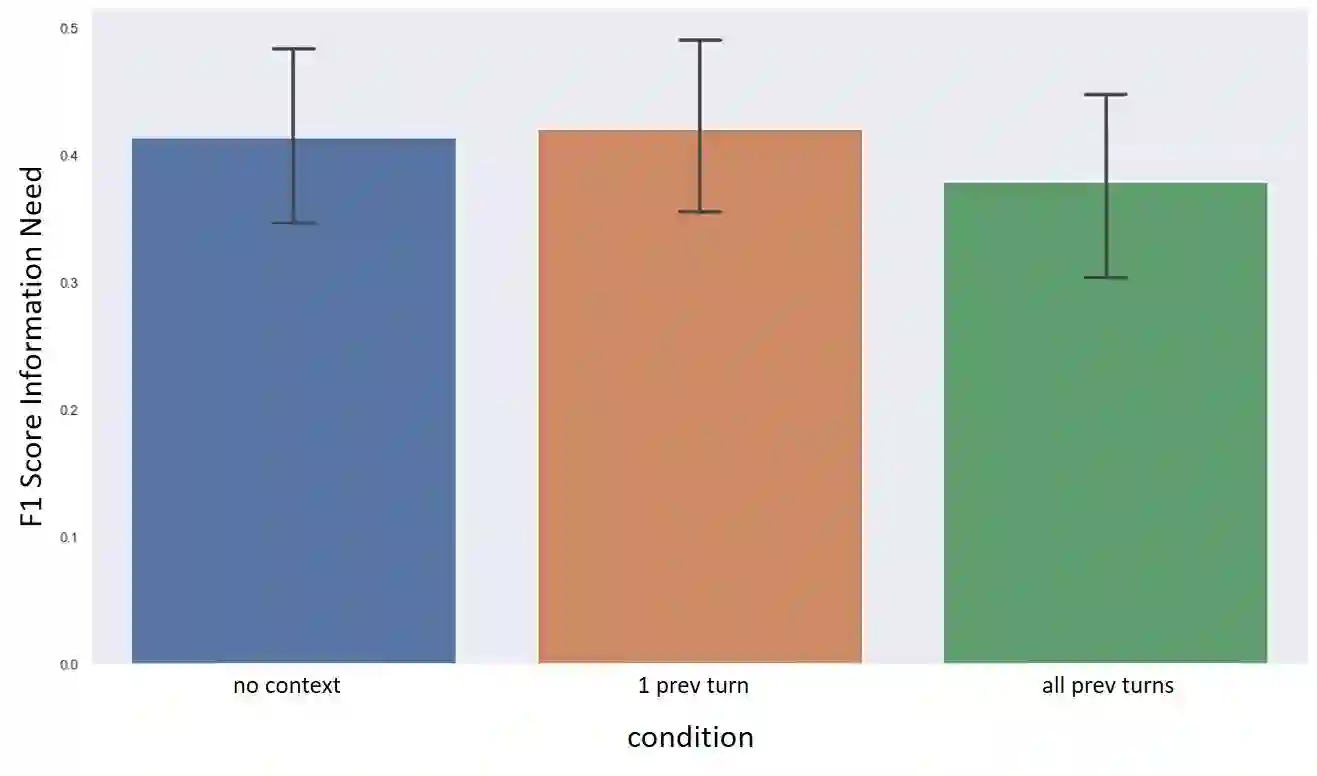
As conversational search becomes more pervasive, it becomes increasingly important to understand the user's underlying information needs when they converse with such systems in diverse domains. We conduct an in-situ study to understand information needs arising in a home cooking context as well as how they are verbally communicated to an assistant. A human experimenter plays this role in our study. Based on the transcriptions of utterances, we derive a detailed hierarchical taxonomy of diverse information needs occurring in this context, which require different levels of assistance to be solved. The taxonomy shows that needs can be communicated through different linguistic means and require different amounts of context to be understood. In a second contribution we perform classification experiments to determine the feasibility of predicting the type of information need a user has during a dialogue using the turn provided. For this multi-label classification problem, we achieve average F1 measures of 40% using BERT-based models. We demonstrate with examples, which types of need are difficult to predict and show why, concluding that models need to include more context information in order to improve both information need classification and assistance to make such systems usable.
翻译:随着谈话搜索越来越普遍,当用户在不同领域与这些系统发生对立时,了解用户的基本信息需求变得日益重要。我们进行了现场研究,以了解家庭烹饪环境中的信息需求以及如何向助理口头传达这些信息需求。在研究中,人类实验者发挥这一作用。根据发言的文字记载,我们得出了在这一背景下出现的不同信息需求的详细等级分类,需要不同程度的援助才能解决。分类学表明,可以通过不同的语言手段沟通需求,需要理解不同数量的背景。在第二项贡献中,我们进行了分类实验,以确定在对话期间使用所提供转机预测用户需要的信息类型的可行性。关于这一多标签分类问题,我们用基于BERT的模型平均达到40%的F1计量。我们用实例来证明,哪些类型的需要是难以预测和说明原因的。我们的结论是,模型需要包含更多的背景信息,以便改进信息需求分类和帮助使这种系统可以使用。