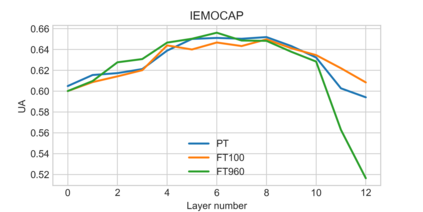
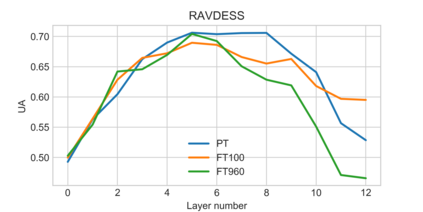
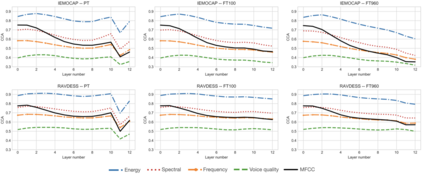
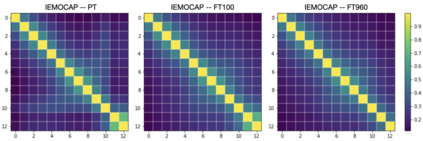
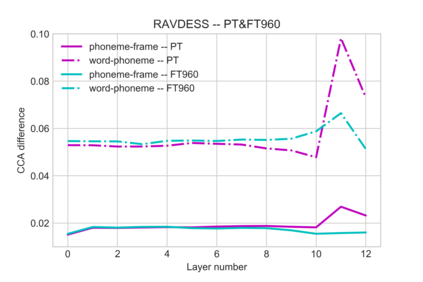
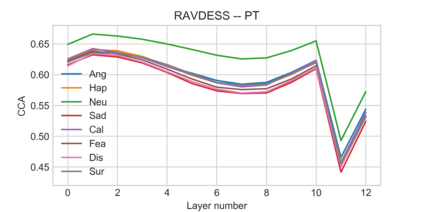
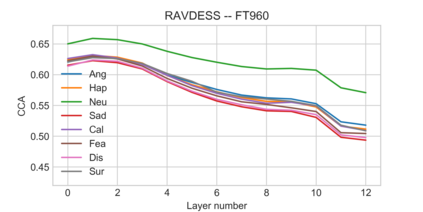
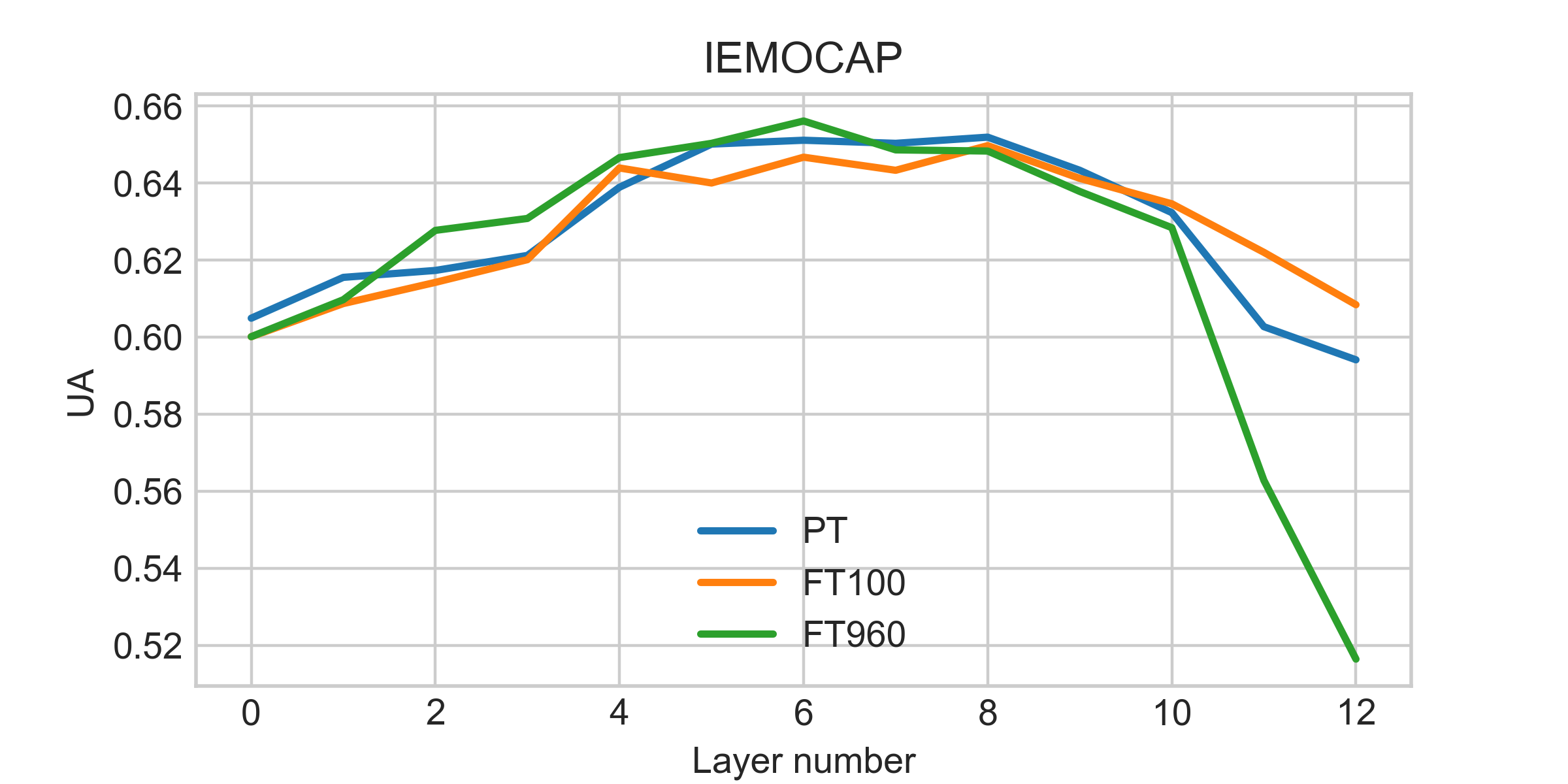
Self-supervised speech models have grown fast during the past few years and have proven feasible for use in various downstream tasks. Some recent work has started to look at the characteristics of these models, yet many concerns have not been fully addressed. In this work, we conduct a study on emotional corpora to explore a popular self-supervised model -- wav2vec 2.0. Via a set of quantitative analysis, we mainly demonstrate that: 1) wav2vec 2.0 appears to discard paralinguistic information that is less useful for word recognition purposes; 2) for emotion recognition, representations from the middle layer alone perform as well as those derived from layer averaging, while the final layer results in the worst performance in some cases; 3) current self-supervised models may not be the optimal solution for downstream tasks that make use of non-lexical features. Our work provides novel findings that will aid future research in this area and theoretical basis for the use of existing models.
翻译:在过去几年里,自我监督的演讲模式发展迅速,事实证明在各种下游任务中可以使用。最近的一些工作已开始研究这些模式的特点,但许多关注问题尚未得到充分解决。在这项工作中,我们对情感团体进行了一项研究,以探索一种流行的自我监督模式 -- -- wav2vec2.0。通过一套定量分析,我们主要表明:(1) wav2vec 2.0似乎抛弃了对文字识别来说不太有用的旁听语言信息;(2) 情感识别,单是中层的表述表现表现表现和从层中得出的表现,而最后一层的表现在某些情况下表现最差;(3) 目前自我监督的模式可能不是使用非传统特征的下游任务的最佳解决办法。我们的工作提供了有助于今后在这一领域开展研究的新发现,以及使用现有模型的理论基础。