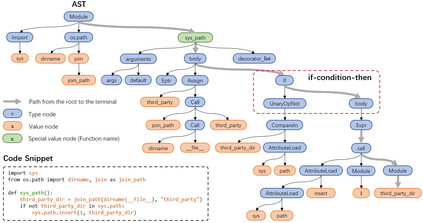
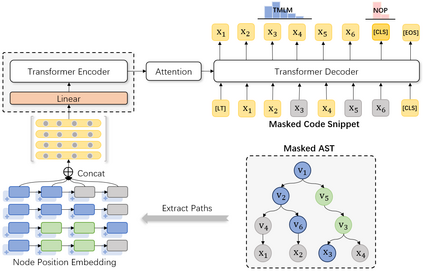
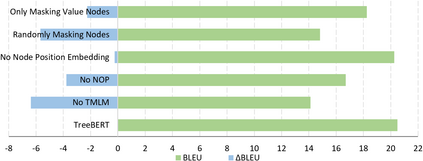
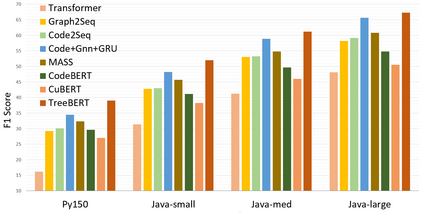
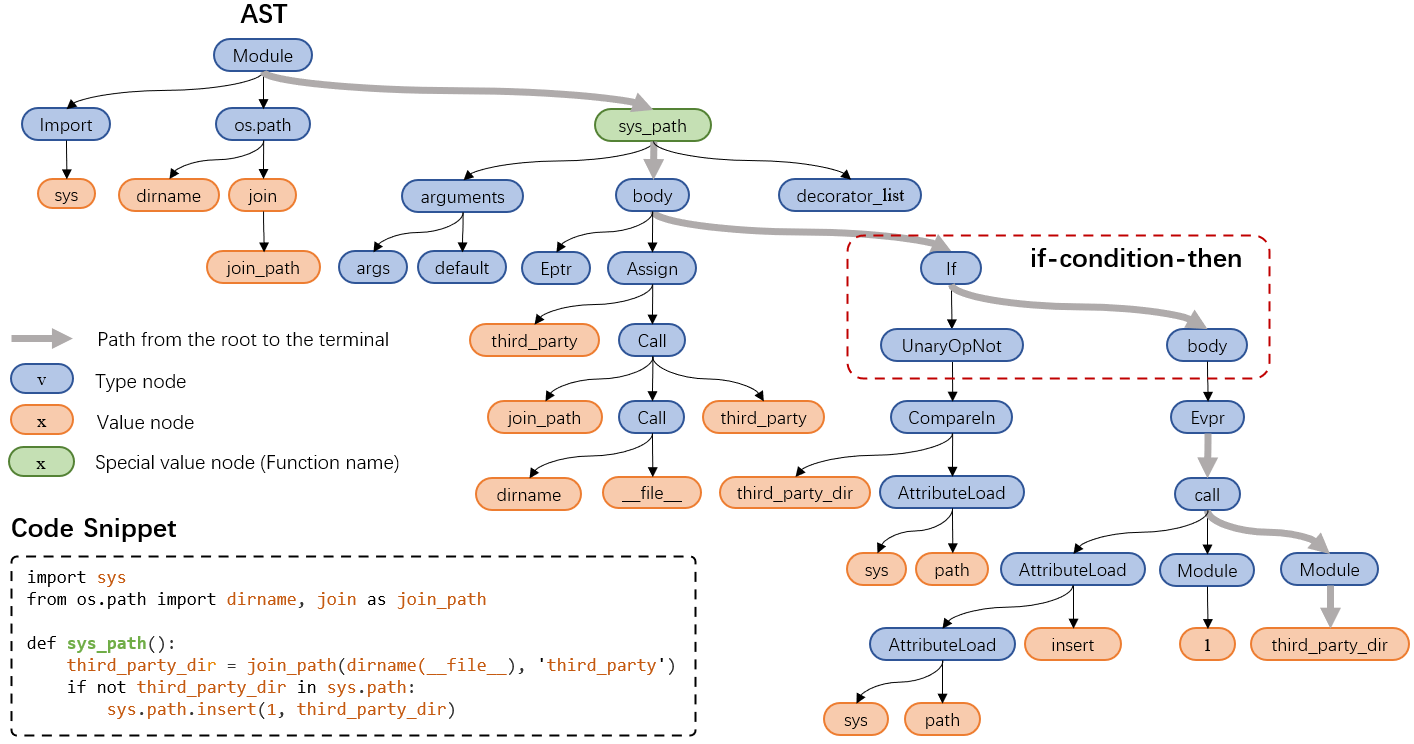
Source code can be parsed into the abstract syntax tree (AST) based on defined syntax rules. However, in pre-training, little work has considered the incorporation of tree structure into the learning process. In this paper, we present TreeBERT, a tree-based pre-trained model for improving programming language-oriented generation tasks. To utilize tree structure, TreeBERT represents the AST corresponding to the code as a set of composition paths and introduces node position embedding. The model is trained by tree masked language modeling (TMLM) and node order prediction (NOP) with a hybrid objective. TMLM uses a novel masking strategy designed according to the tree's characteristics to help the model understand the AST and infer the missing semantics of the AST. With NOP, TreeBERT extracts the syntactical structure by learning the order constraints of nodes in AST. We pre-trained TreeBERT on datasets covering multiple programming languages. On code summarization and code documentation tasks, TreeBERT outperforms other pre-trained models and state-of-the-art models designed for these tasks. Furthermore, TreeBERT performs well when transferred to the pre-trained unseen programming language.
翻译:源代码可以根据定义的语法规则对抽象的语法树( AST) 进行分解。 但是, 在培训前, 很少考虑将树结构纳入学习过程。 在本文中, 我们展示了一个基于树的预培训模型, 用于改进基于语言的生成任务。 要使用树结构, 树BERT 代表与代码相对应的AST作为一套组成路径, 并引入节点嵌入。 该模型由树蒙面语言模型( TMLM) 和节点顺序预测( NOP) 以混合目标来培训。 TMLM 使用一种根据树特性设计的新颖的遮罩战略来帮助模型理解 AST, 并推断缺少的语义 。 与 NOP 相比, 树BERT 提取了与代码对应的合成结构, 学习了 AST 中节点的顺序限制。 我们事先培训过的树BERT, 有关包含多种编程语言的数据集。 关于代码和代码拼写和代码文档任务, TreBERT 超越了其他预先训练过的模型,, 将这些模型转移到了 。