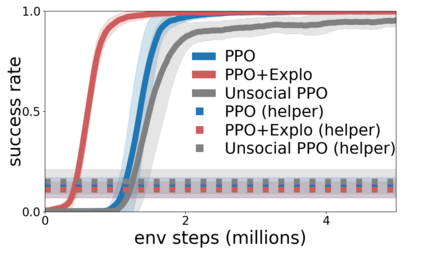
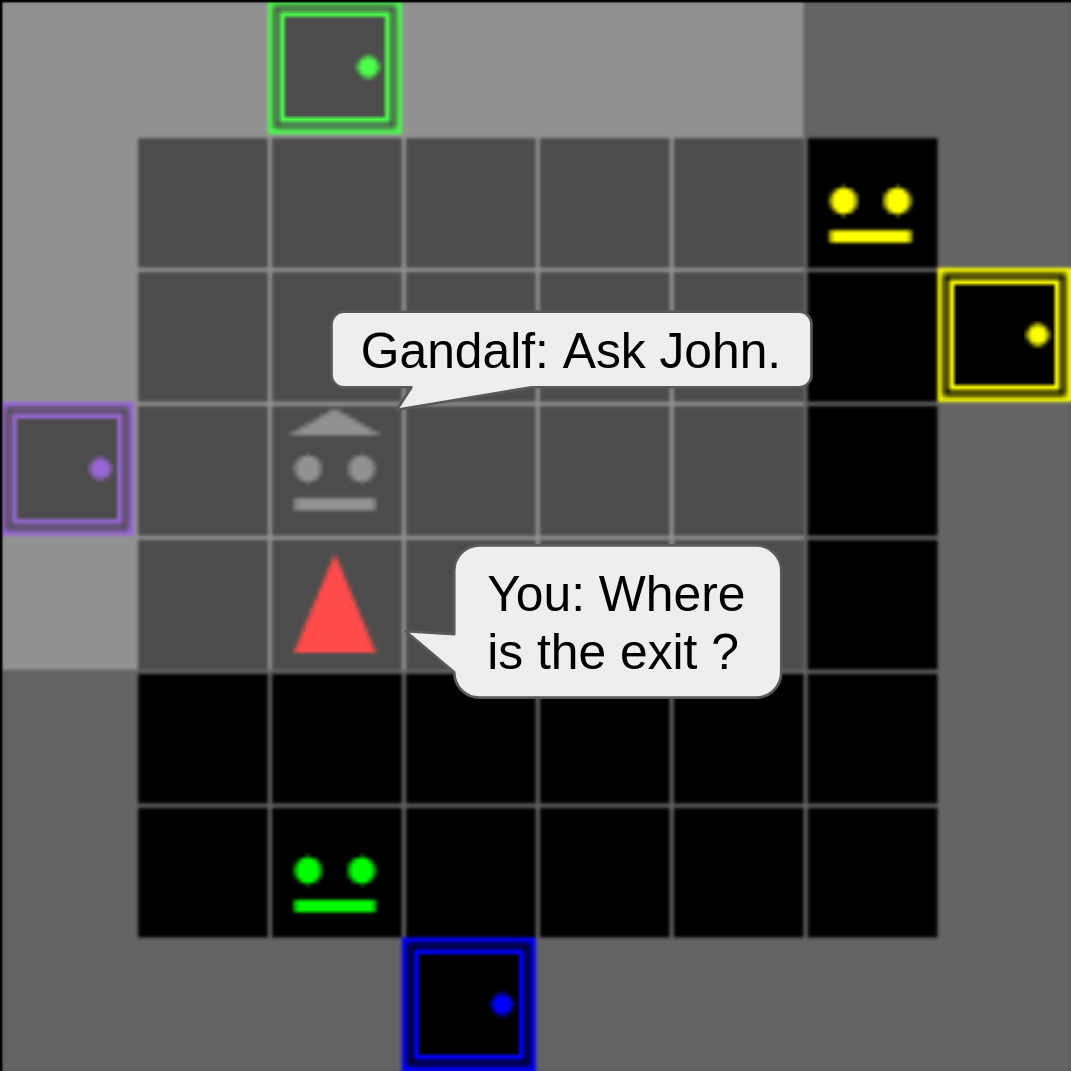
Building embodied autonomous agents capable of participating in social interactions with humans is one of the main challenges in AI. Within the Deep Reinforcement Learning (DRL) field, this objective motivated multiple works on embodied language use. However, current approaches focus on language as a communication tool in very simplified and non-diverse social situations: the "naturalness" of language is reduced to the concept of high vocabulary size and variability. In this paper, we argue that aiming towards human-level AI requires a broader set of key social skills: 1) language use in complex and variable social contexts; 2) beyond language, complex embodied communication in multimodal settings within constantly evolving social worlds. We explain how concepts from cognitive sciences could help AI to draw a roadmap towards human-like intelligence, with a focus on its social dimensions. As a first step, we propose to expand current research to a broader set of core social skills. To do this, we present SocialAI, a benchmark to assess the acquisition of social skills of DRL agents using multiple grid-world environments featuring other (scripted) social agents. We then study the limits of a recent SOTA DRL approach when tested on SocialAI and discuss important next steps towards proficient social agents. Videos and code are available at https://sites.google.com/view/socialai.
翻译:在深入强化学习(DRL)领域,这个目标激发了多种关于语言应用的多重工作。然而,目前的方法侧重于语言作为非常简化和非多样化的社会状况中的交流工具:语言的“自然性”已沦为高词汇大小和变异的概念。在本文件中,我们提出,实现人类层面的AI需要更广泛的一套关键社会技能:(1) 在复杂和多变的社会环境中使用语言;(2) 在语言之外,在不断演变的社会世界中多式环境中的复杂通信。我们解释了认知科学的概念如何帮助AI绘制人类智能路线图,重点是其社会层面。作为第一步,我们提议将当前研究扩大到更广泛的核心社会技能。为了做到这一点,我们介绍社会AI,一个基准,用以评估DRL代理人利用多种网格-世界环境获得社会技能的情况。我们随后研究了SATA DRL方法在不断演变的社交世界环境中的局限性。我们随后在社会AI/Profigle Profiols上测试并讨论未来重要步骤。