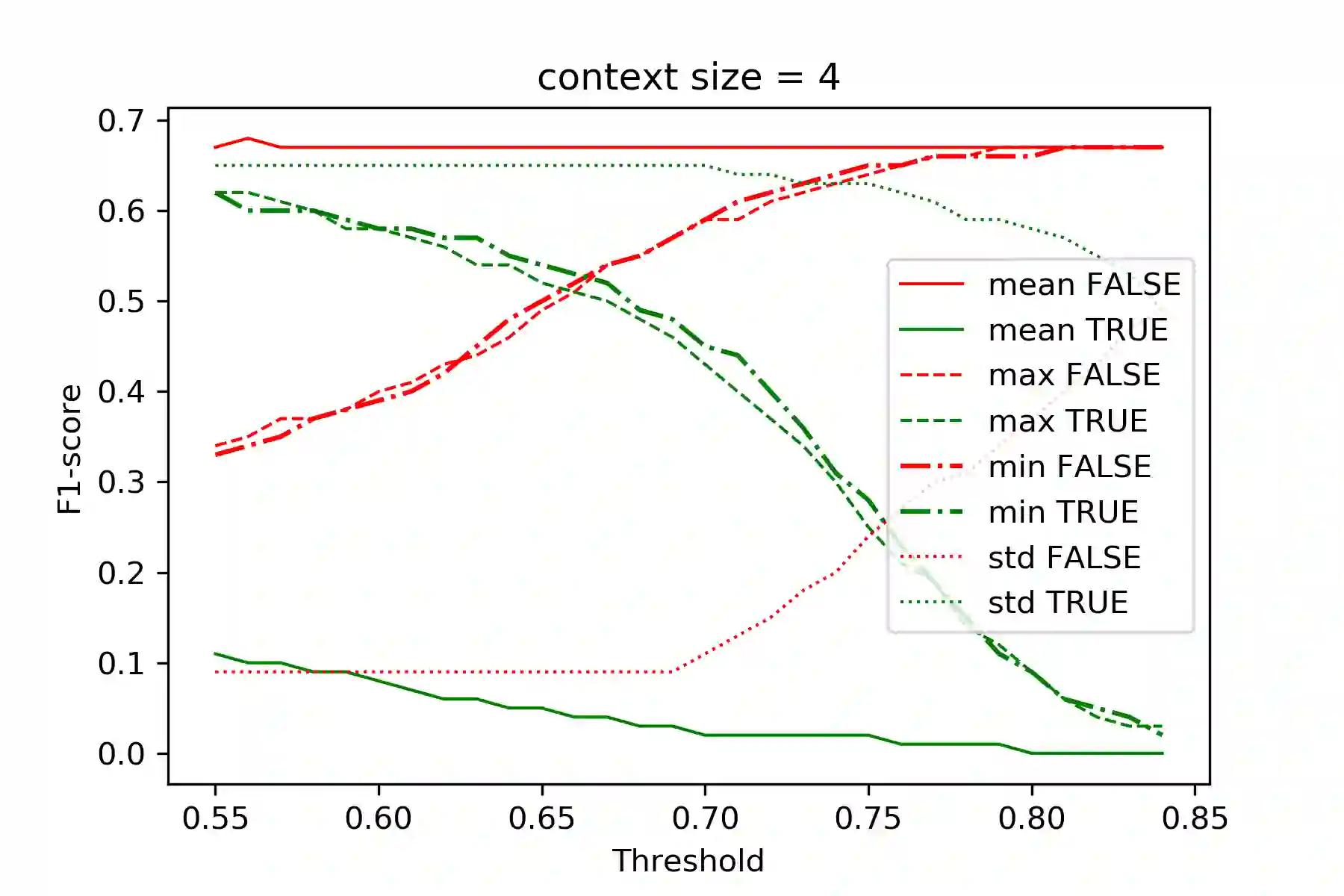
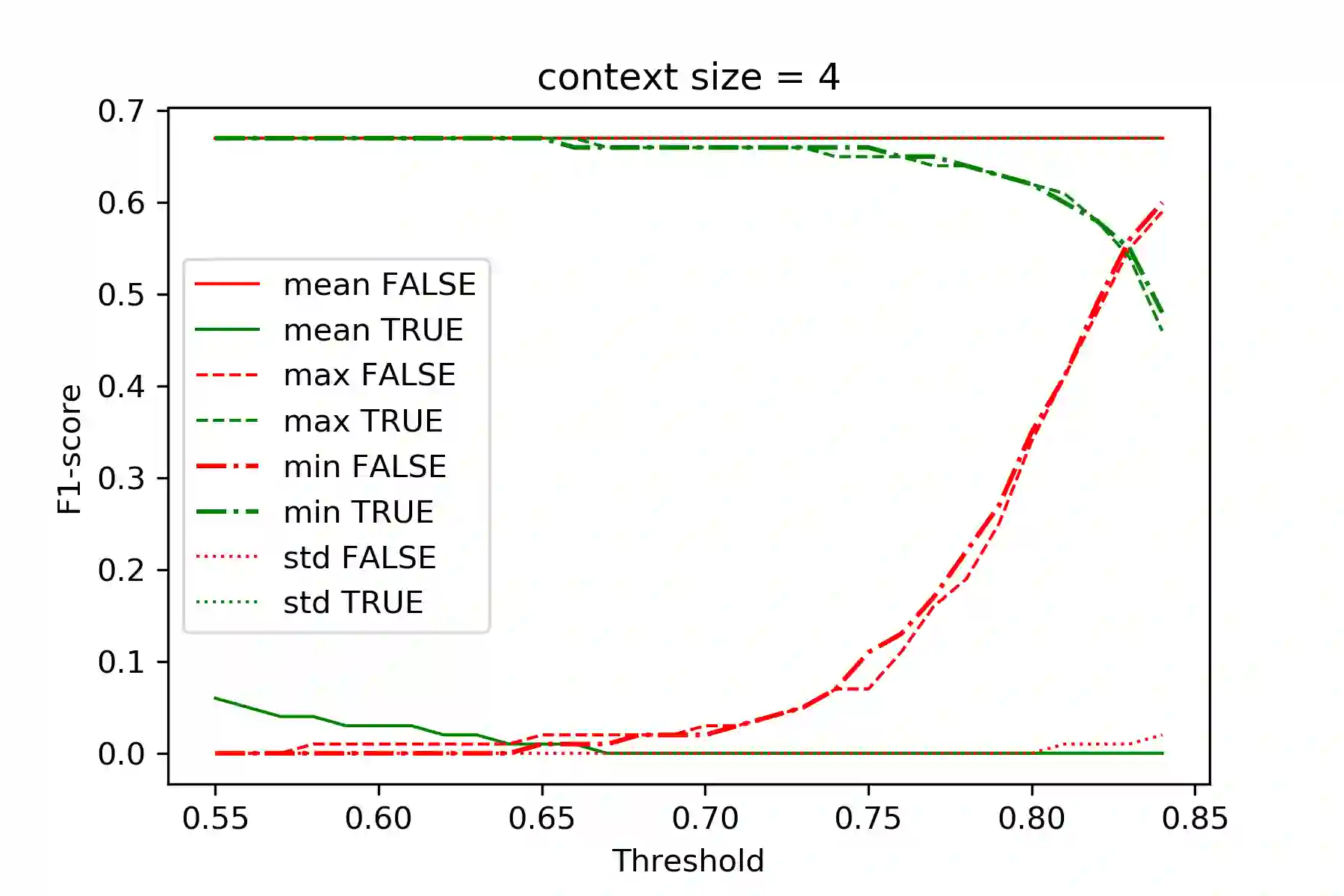
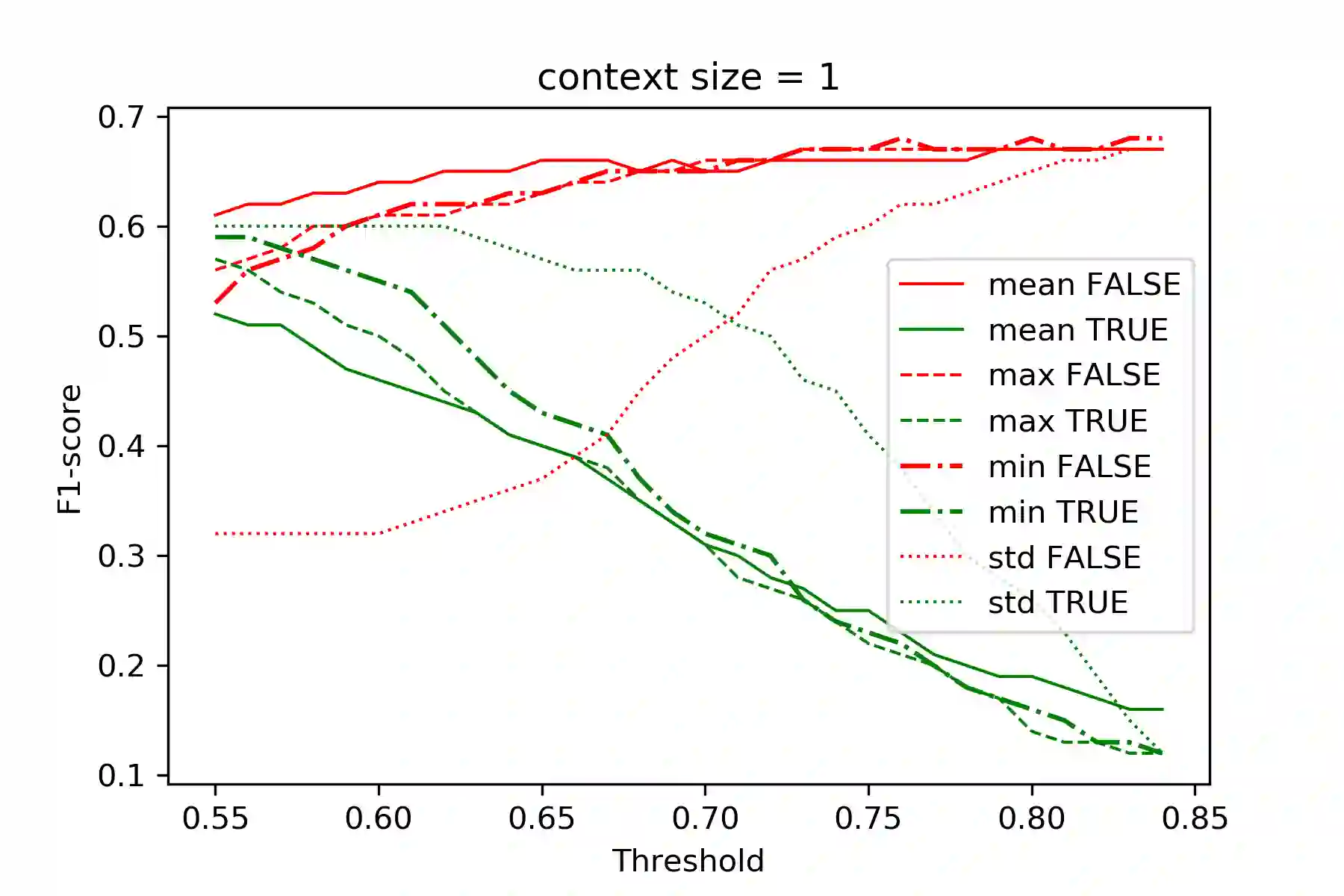
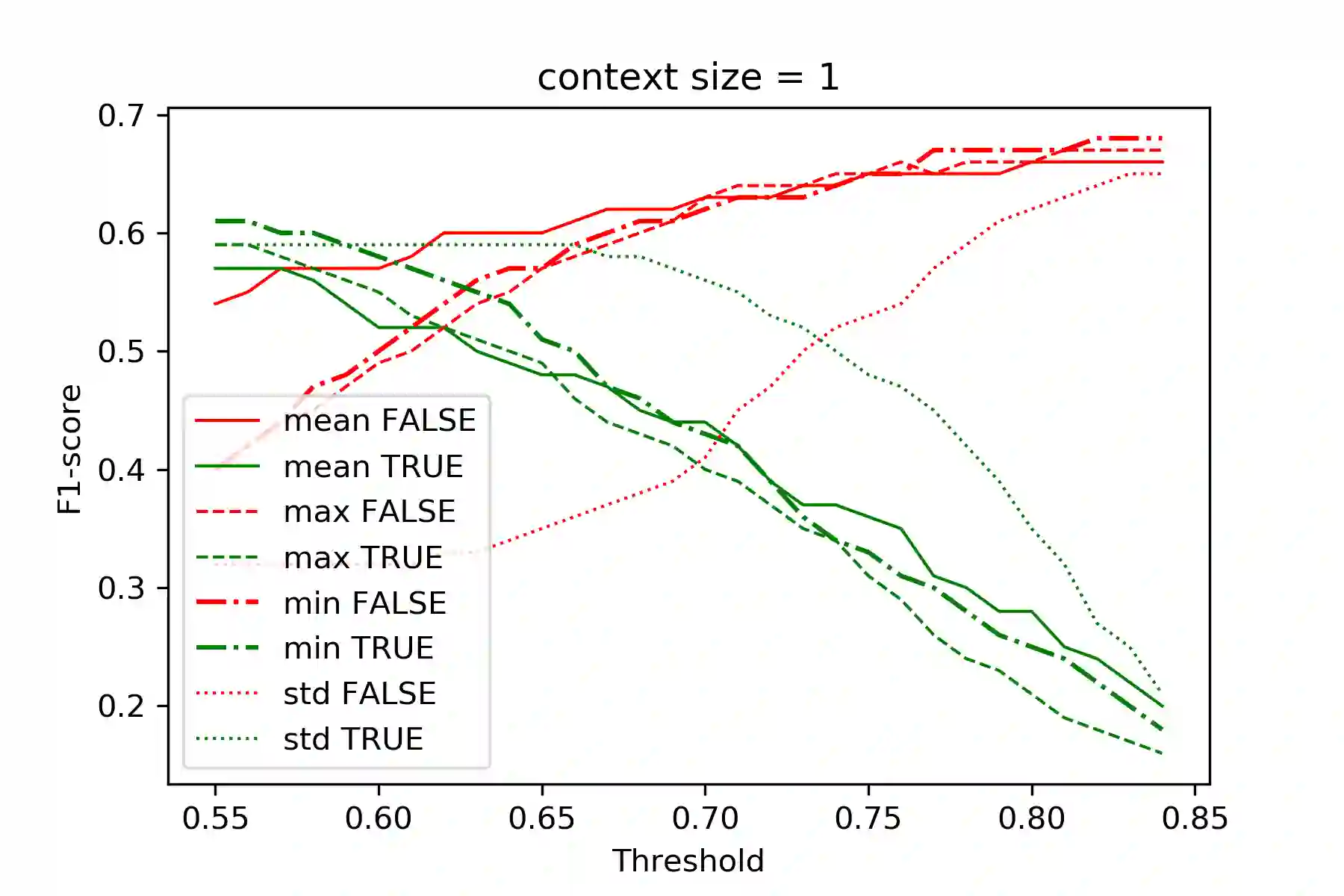
This paper presents a set of experiments to evaluate and compare between the performance of using CBOW Word2Vec and Lemma2Vec models for Arabic Word-in-Context (WiC) disambiguation without using sense inventories or sense embeddings. As part of the SemEval-2021 Shared Task 2 on WiC disambiguation, we used the dev.ar-ar dataset (2k sentence pairs) to decide whether two words in a given sentence pair carry the same meaning. We used two Word2Vec models: Wiki-CBOW, a pre-trained model on Arabic Wikipedia, and another model we trained on large Arabic corpora of about 3 billion tokens. Two Lemma2Vec models was also constructed based on the two Word2Vec models. Each of the four models was then used in the WiC disambiguation task, and then evaluated on the SemEval-2021 test.ar-ar dataset. At the end, we reported the performance of different models and compared between using lemma-based and word-based models.
翻译:本文介绍了一套实验,用以评价和比较使用CBOW Word2Vec和Lemma2Vec模型进行阿拉伯语Word-in-Context(WIC)脱混的功能,而没有使用感知盘点或感知嵌入器。作为SemEval-2021关于WAC脱混的共有任务2的一部分,我们使用dev.ar-ar数据集(2k句)来决定某一句中的两个词是否具有相同的含义。我们使用了两个Wiki-CBOW模型,即阿拉伯维基百科预先培训的模型,以及另一个我们培训的大约30亿个符号的大型阿拉伯公司模型。两个Lemma2Vec模型也是以两个Word2Vec模型为基础建造的。四个模型中的每一个后来都用于WIC脱混混工作,然后对SemEval-2021测试.ar-ar数据集进行了评估。在结尾,我们报告了不同模型的性能,并比较了使用伦玛模型和单词模型。