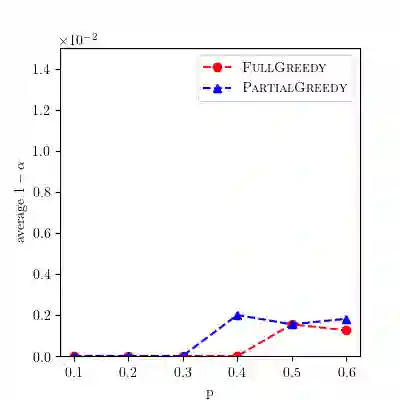
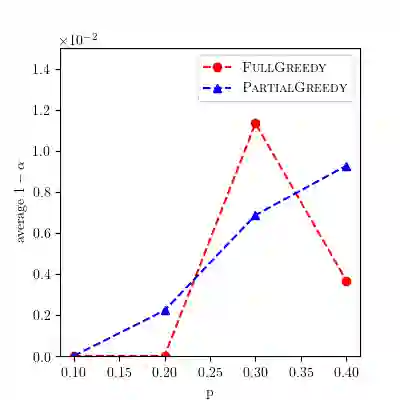
We analyze greedy algorithms for the Hierarchical Aggregation (HAG) problem, a strategy introduced in [Jia et al., KDD 2020] for speeding up learning on Graph Neural Networks (GNNs). The idea of HAG is to identify and remove redundancies in computations performed when training GNNs. The associated optimization problem is to identify and remove the most redundancies. Previous work introduced a greedy approach for the HAG problem and claimed a 1-1/e approximation factor. We show by example that this is not correct, and one cannot hope for better than a 1/2 approximation factor. We prove that this greedy algorithm does satisfy some (weaker) approximation guarantee, by showing a new connection between the HAG problem and maximum matching problems in hypergraphs. We also introduce a second greedy algorithm which can out-perform the first one, and we show how to implement it efficiently in some parameter regimes. Finally, we introduce some greedy heuristics that are much faster than the above greedy algorithms, and we demonstrate that they perform well on real-world graphs.
翻译:我们分析关于等级聚合(HAG)问题的贪婪算法,这是[Jia等人,KDD 2020]为加速在图形神经网络(GNNs)上学习而推出的一项战略。HAG的想法是确定并消除在培训GNNs时进行的计算中的冗余。相关的优化问题在于识别并消除最冗余的冗余。先前的工作为HAG问题引入了贪婪的方法,并主张了1-1/e近似系数。我们通过实例表明,这不正确,而且不能指望比1/2近似系数更好。我们证明,这种贪婪算法确实满足了某些(弱)近似保证,我们展示了HAG问题与高数据中最大匹配问题之间的新联系。我们还引入了第二种贪婪算法,可以超越第一个,我们展示了在某些参数系统中如何有效地实施。最后,我们引入了一些比以上贪婪算法快得多的贪婪的超值,我们展示了它们在真实世界图表上的表现良好。