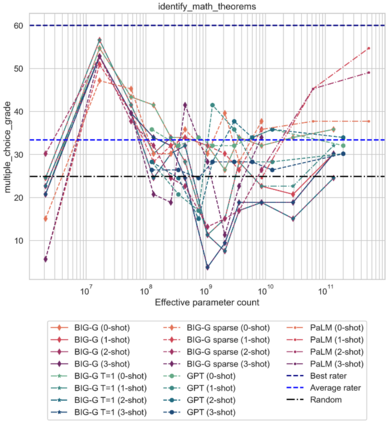
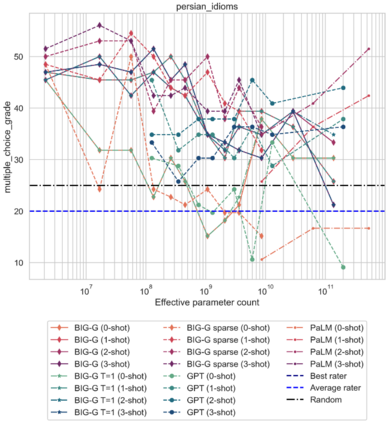
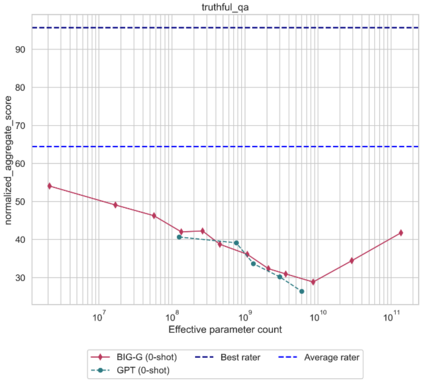
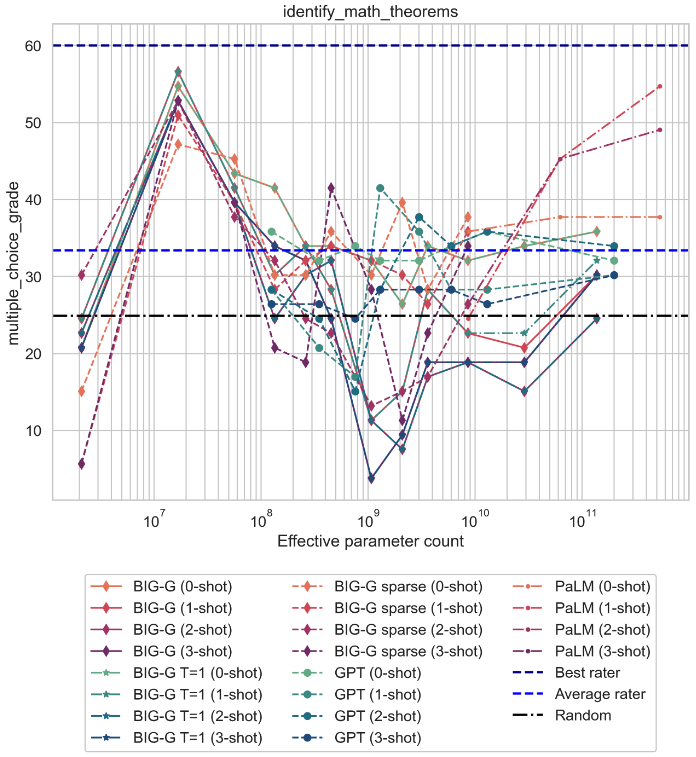
Although scaling language models improves performance on a range of tasks, there are apparently some scenarios where scaling hurts performance. For instance, the Inverse Scaling Prize Round 1 identified four ''inverse scaling'' tasks, for which performance gets worse for larger models. These tasks were evaluated on models of up to 280B parameters, trained up to 500 zettaFLOPs of compute. This paper takes a closer look at these four tasks. We evaluate models of up to 540B parameters, trained on five times more compute than those evaluated in the Inverse Scaling Prize. With this increased range of model sizes and training compute, three out of the four tasks exhibit what we call ''U-shaped scaling'' -- performance decreases up to a certain model size, and then increases again up to the largest model evaluated. One hypothesis is that U-shaped scaling occurs when a task comprises a ''true task'' and a ''distractor task''. Medium-size models can do the distractor task, which hurts performance, while only large-enough models can ignore the distractor task and do the true task. The existence of U-shaped scaling implies that inverse scaling may not hold for larger models. Second, we evaluate the inverse scaling tasks using chain-of-thought (CoT) prompting, in addition to basic prompting without CoT. With CoT prompting, all four tasks show either U-shaped scaling or positive scaling, achieving perfect solve rates on two tasks and several sub-tasks. This suggests that the term "inverse scaling task" is under-specified -- a given task may be inverse scaling for one prompt but positive or U-shaped scaling for a different prompt.
翻译:虽然在一系列任务上推广语言模型会提高绩效,但显然有些情况是,在一系列任务上,扩展语言模型会提高绩效。例如,反向扩展奖第一回合确定了四个“反向缩放”任务,其中四个“反向缩放”任务比较大的模型要差得多。这些任务在最多280B参数的模型上进行了评估,训练了最多500 zettaFLOP 的计算。本文对这四个任务进行了更仔细的审视。我们评估了最多540B参数的模型,比反向缩放奖中评估的参数要高五倍的计算。随着模型规模和培训的计算范围扩大,四个任务中的三个显示我们所谓的“U型缩放”任务中的四个“反向缩放”任务中的四个“反向反向缩放”任务中的四个。随着U型任务的规模扩大,在二进式任务中,“向更大幅度的缩放”的U型任务的存在意味着我们不会保持“真实的缩放速度。