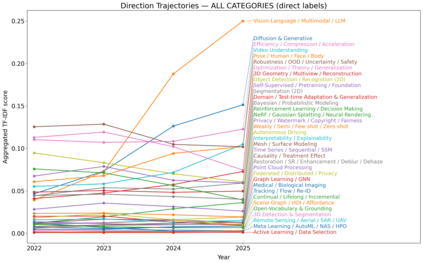
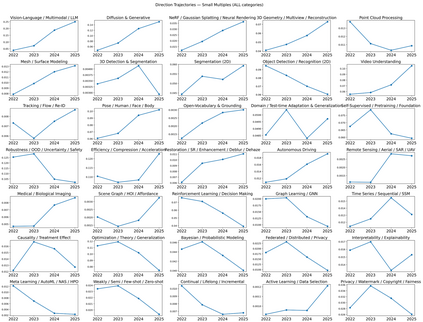
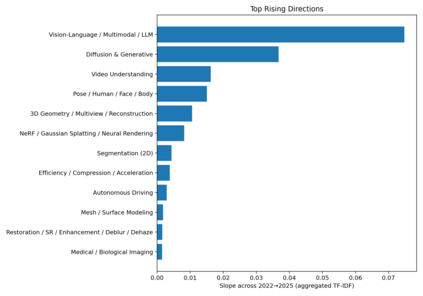
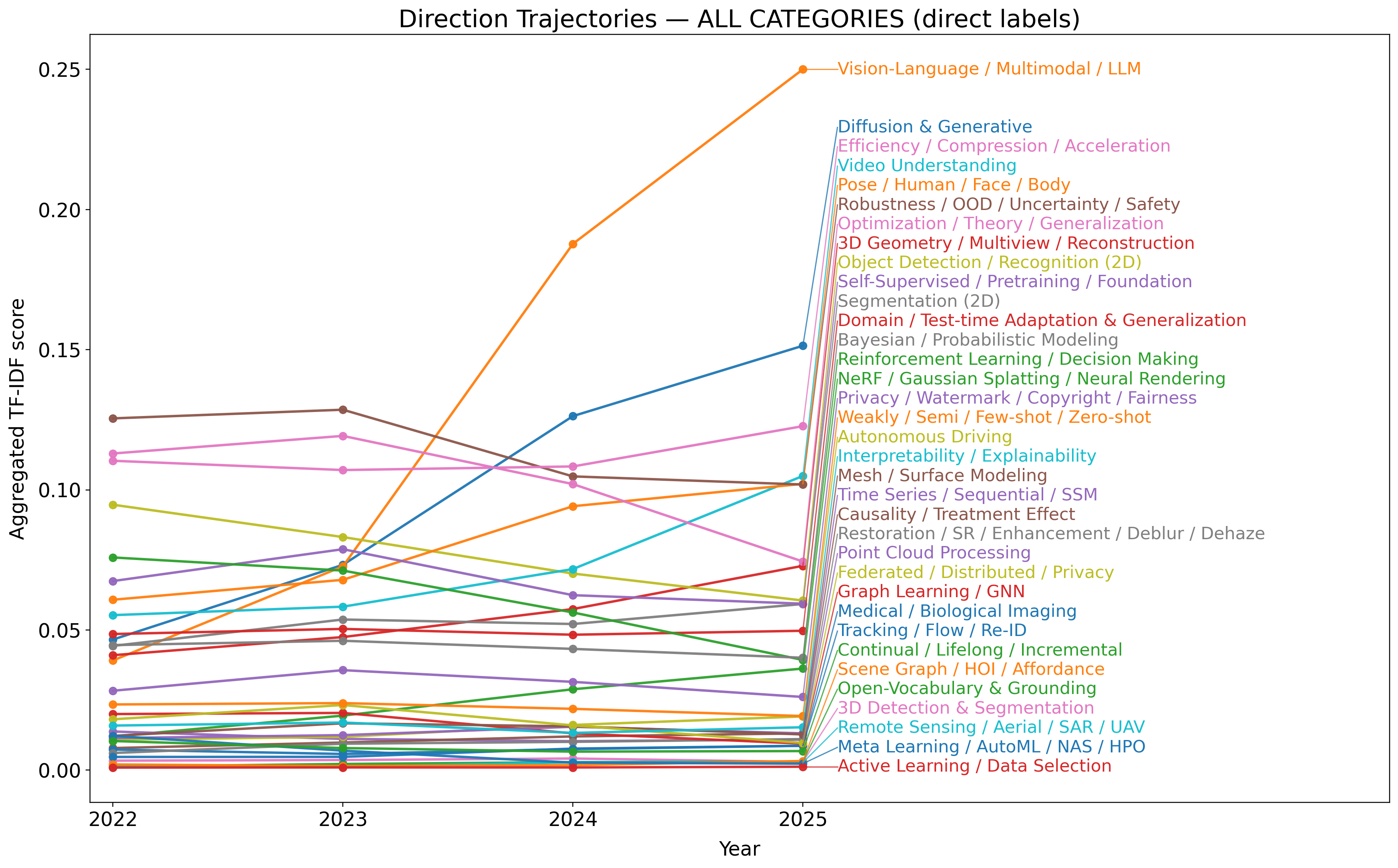
We present a transparent, reproducible measurement of research trends across 26,104 accepted papers from CVPR, ICLR, and NeurIPS spanning 2023-2025. Titles and abstracts are normalized, phrase-protected, and matched against a hand-crafted lexicon to assign up to 35 topical labels and mine fine-grained cues about tasks, architectures, training regimes, objectives, datasets, and co-mentioned modalities. The analysis quantifies three macro shifts: (1) a sharp rise of multimodal vision-language-LLM work, which increasingly reframes classic perception as instruction following and multi-step reasoning; (2) steady expansion of generative methods, with diffusion research consolidating around controllability, distillation, and speed; and (3) resilient 3D and video activity, with composition moving from NeRFs to Gaussian splatting and a growing emphasis on human- and agent-centric understanding. Within VLMs, parameter-efficient adaptation like prompting/adapters/LoRA and lightweight vision-language bridges dominate; training practice shifts from building encoders from scratch to instruction tuning and finetuning strong backbones; contrastive objectives recede relative to cross-entropy/ranking and distillation. Cross-venue comparisons show CVPR has a stronger 3D footprint and ICLR the highest VLM share, while reliability themes such as efficiency or robustness diffuse across areas. We release the lexicon and methodology to enable auditing and extension. Limitations include lexicon recall and abstract-only scope, but the longitudinal signals are consistent across venues and years.
翻译:暂无翻译