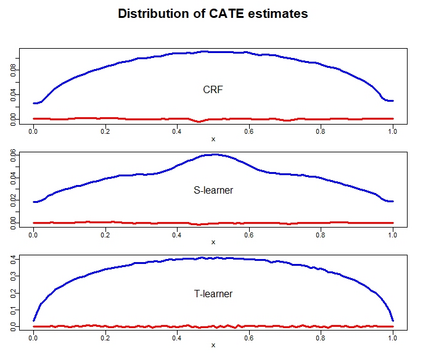
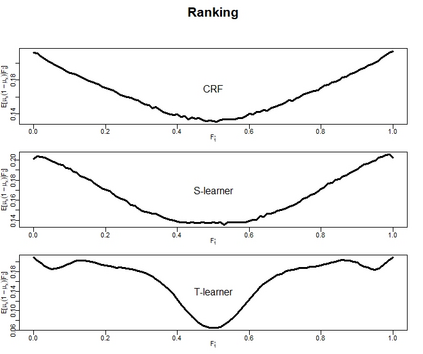
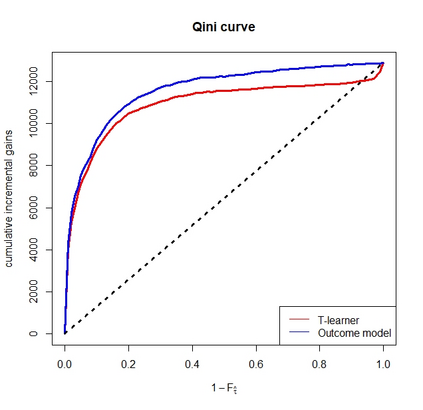
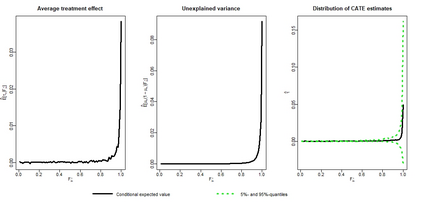
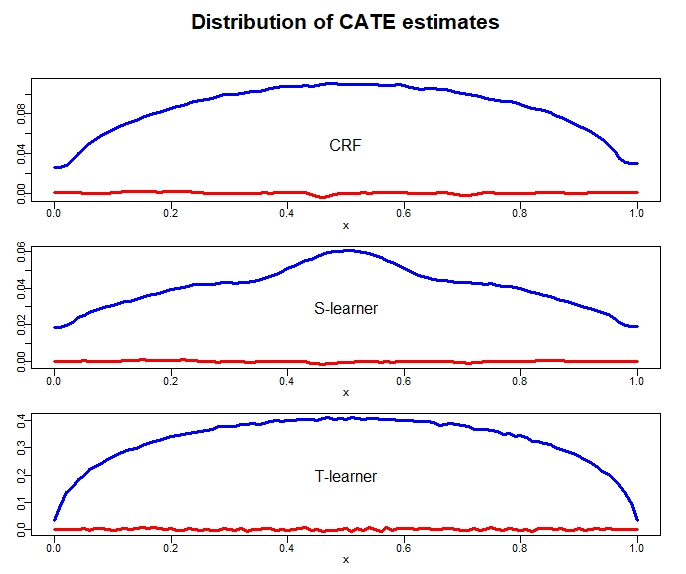
There are various applications, where companies need to decide to which individuals they should best allocate treatment. To support such decisions, uplift models are applied to predict treatment effects on an individual level. Based on the predicted treatment effects, individuals can be ranked and treatment allocation can be prioritized according to this ranking. An implicit assumption, which has not been doubted in the previous uplift modeling literature, is that this treatment prioritization approach tends to bring individuals with high treatment effects to the top and individuals with low treatment effects to the bottom of the ranking. In our research, we show that heteroskedastictity in the training data can cause a bias of the uplift model ranking: individuals with the highest treatment effects can get accumulated in large numbers at the bottom of the ranking. We explain theoretically how heteroskedasticity can bias the ranking of uplift models and show this process in a simulation and on real-world data. We argue that this problem of ranking bias due to heteroskedasticity might occur in many real-world applications and requires modification of the treatment prioritization to achieve an efficient treatment allocation.
翻译:暂无翻译