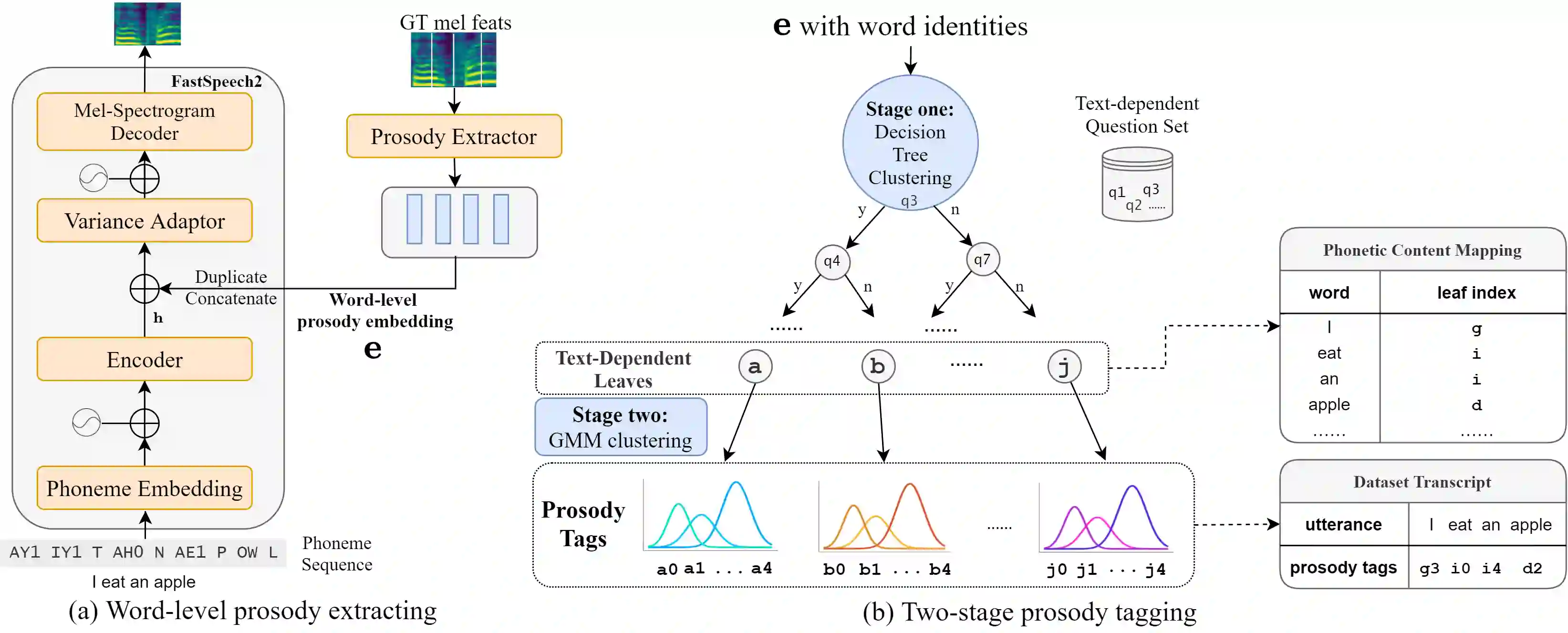
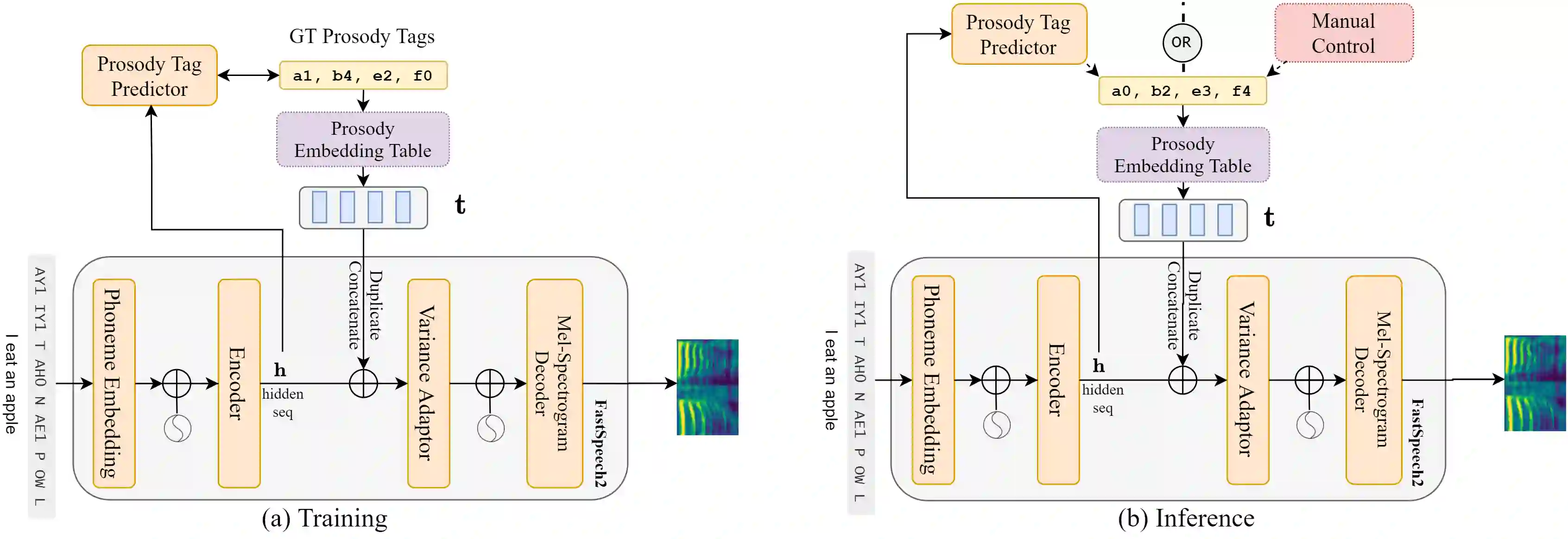
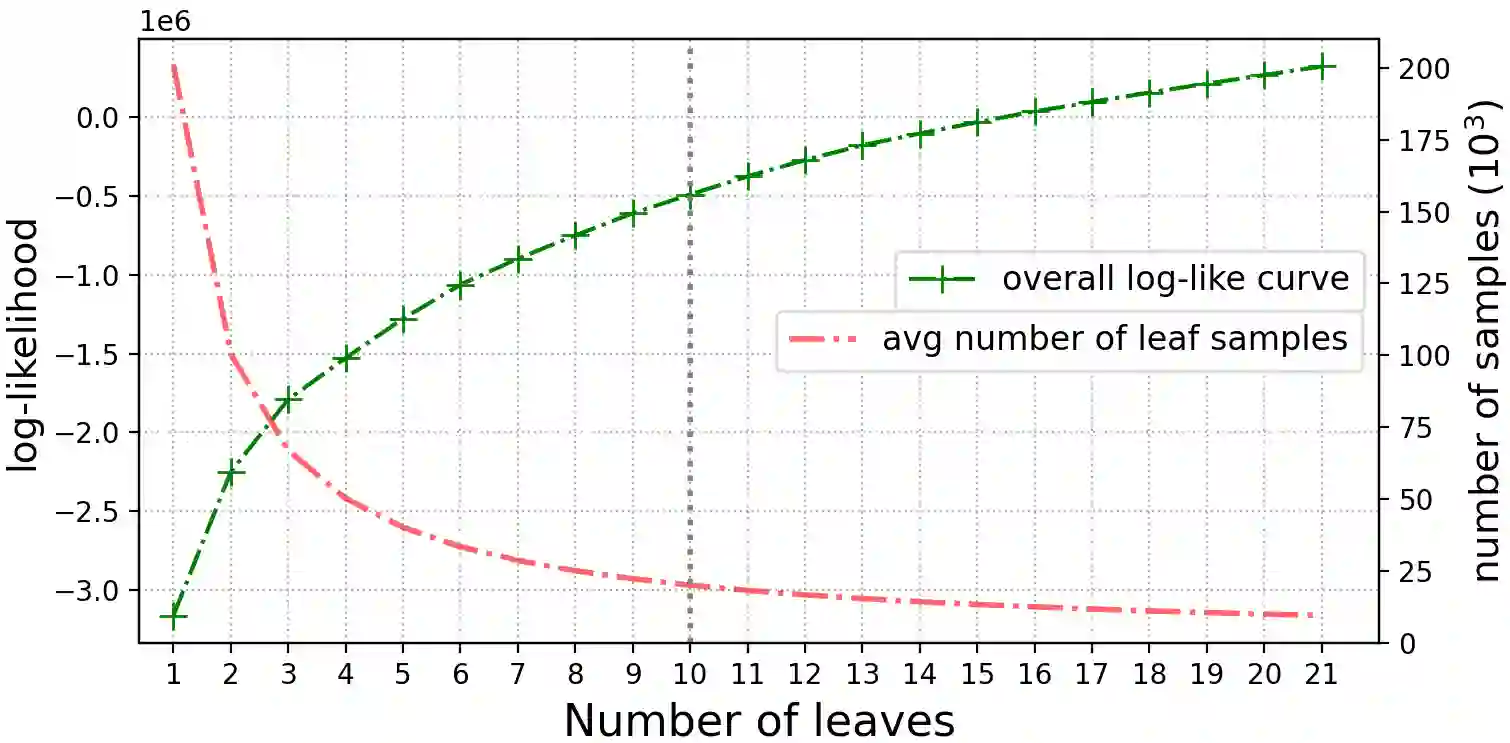
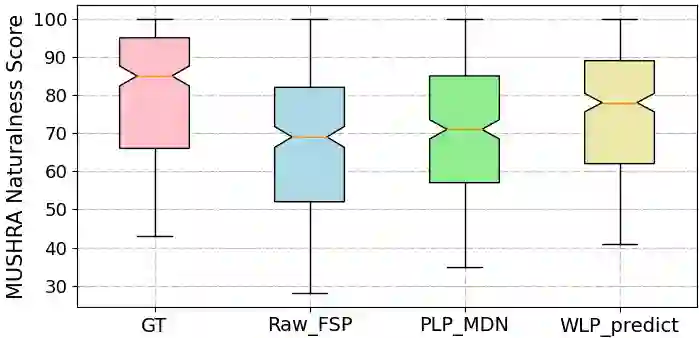
Although word-level prosody modeling in neural text-to-speech (TTS) has been investigated in recent research for diverse speech synthesis, it is still challenging to control speech synthesis manually without a specific reference. This is largely due to lack of word-level prosody tags. In this work, we propose a novel approach for unsupervised word-level prosody tagging with two stages, where we first group the words into different types with a decision tree according to their phonetic content and then cluster the prosodies using GMM within each type of words separately. This design is based on the assumption that the prosodies of different type of words, such as long or short words, should be tagged with different label sets. Furthermore, a TTS system with the derived word-level prosody tags is trained for controllable speech synthesis. Experiments on LJSpeech show that the TTS model trained with word-level prosody tags not only achieves better naturalness than a typical FastSpeech2 model, but also gains the ability to manipulate word-level prosody.
翻译:虽然最近对各种语音合成的研究已经调查了神经文本到语音(TTS)中的字级假模模型(LTS),但人工控制语音合成仍具有挑战性,这在很大程度上是因为缺少字级假模标记。在这项工作中,我们提出了一种新颖的方法,用于无监管的字级假模标记,分为两个阶段,我们首先将单词分为不同类型,按其语音内容将决定树分为决定型号,然后将使用GMM的预模单独组合在每类单词中。这一设计的基础是假设,不同类型单词的预言,如长词或短字,应该用不同的标签标注。此外,带有衍生的字级假模标记的TTS系统受过可控语音合成培训。LJSpeech实验显示,用字级假模标训练的TTS模型不仅比典型的快式Speech2模型更自然,而且还获得了调字级预模的能力。