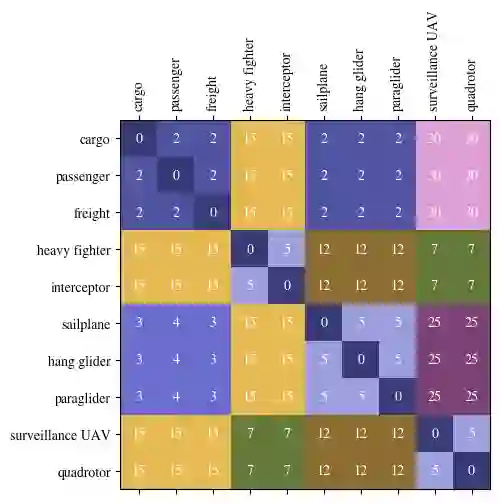
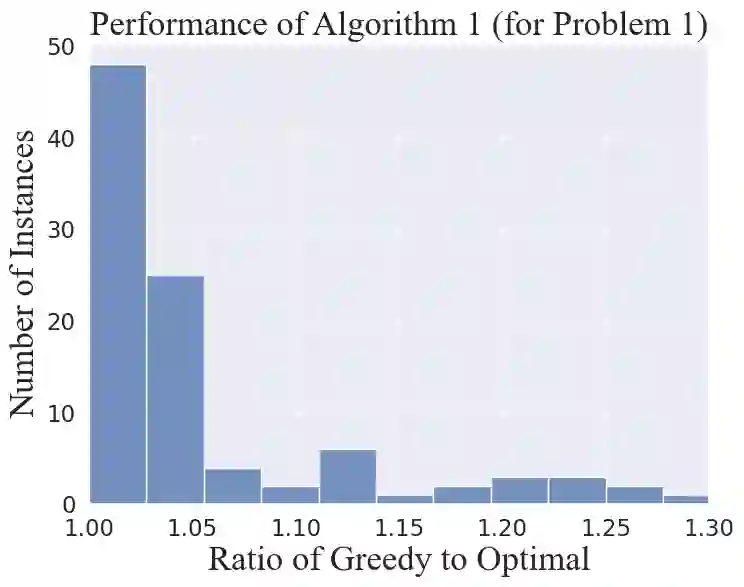
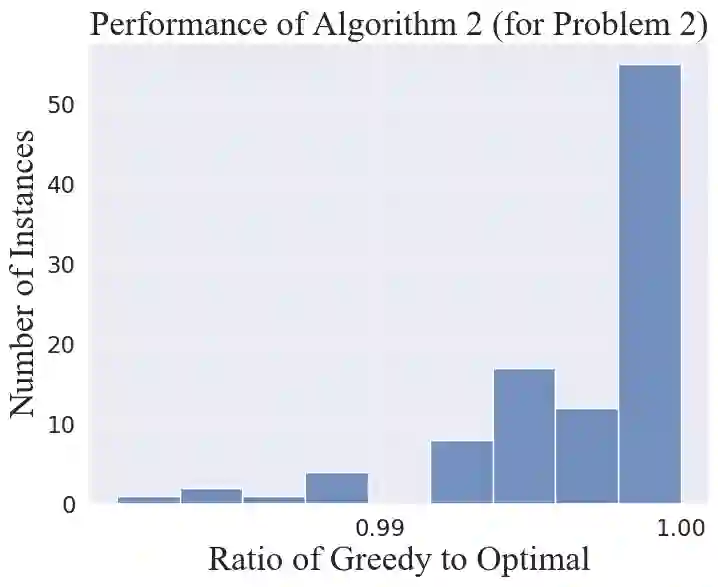
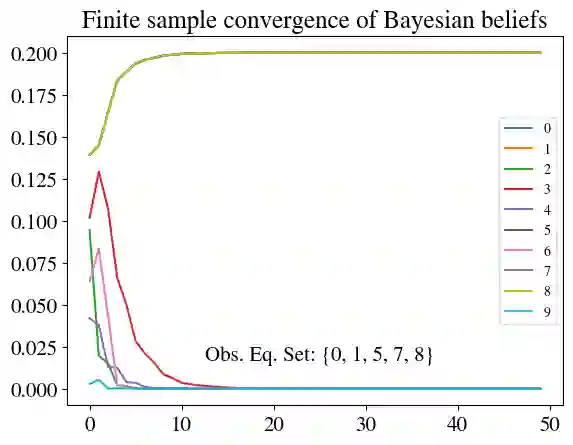
We consider the problem of selecting an optimal subset of information sources for a hypothesis testing/classification task where the goal is to identify the true state of the world from a finite set of hypotheses, based on finite observation samples from the sources. In order to characterize the learning performance, we propose a misclassification penalty framework, which enables non-uniform treatment of different misclassification errors. In a centralized Bayesian learning setting, we study two variants of the subset selection problem: (i) selecting a minimum cost information set to ensure that the maximum penalty of misclassifying the true hypothesis remains bounded and (ii) selecting an optimal information set under a limited budget to minimize the maximum penalty of misclassifying the true hypothesis. Under mild assumptions, we prove that the objective (or constraints) of these combinatorial optimization problems are weak (or approximate) submodular, and establish high-probability performance guarantees for greedy algorithms. Further, we propose an alternate metric for information set selection which is based on the total penalty of misclassification. We prove that this metric is submodular and establish near-optimal guarantees for the greedy algorithms for both the information set selection problems. Finally, we present numerical simulations to validate our theoretical results over several randomly generated instances.
翻译:暂无翻译