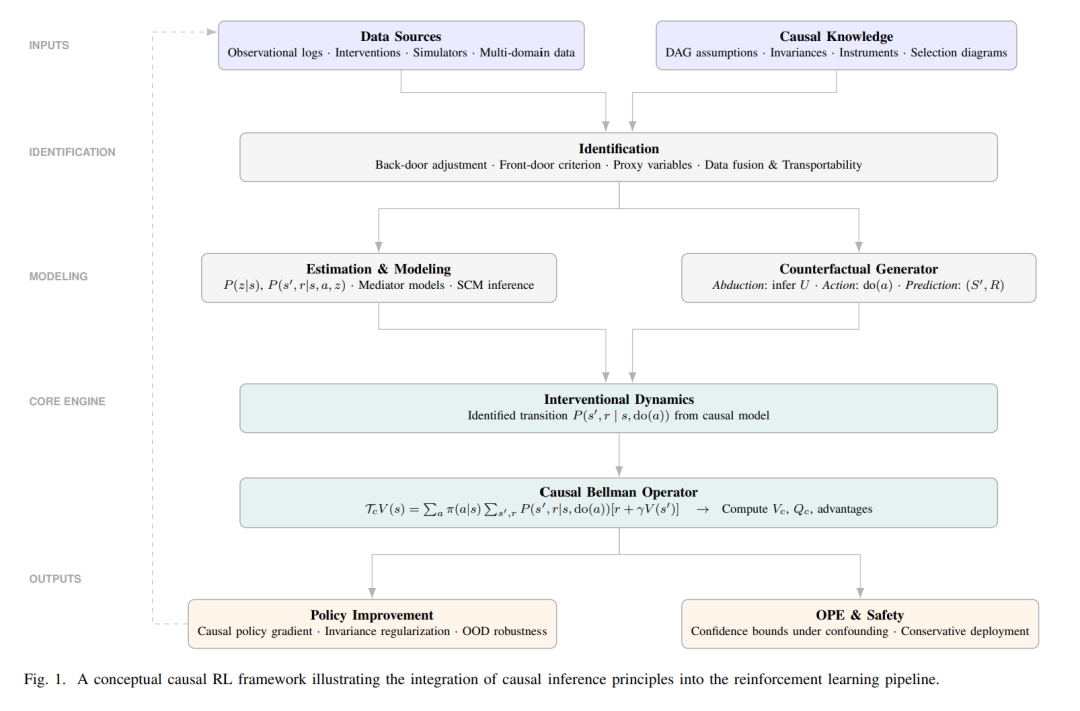
将因果推断(Causal Inference,CI)与强化学习(Reinforcement Learning,RL)相结合,已成为应对传统强化学习若干关键局限性的一个有前景的范式,这些局限性包括可解释性不足、鲁棒性欠缺以及泛化能力失效等问题。传统的强化学习方法通常依赖相关性驱动的决策机制,在面对分布偏移、混杂变量以及动态环境时往往表现不佳。因果强化学习(Causal Reinforcement Learning,CRL)通过显式建模因果关系,利用因果推断的基本原理,为上述挑战提供了有力的解决思路。 在本文综述中,我们系统性地回顾了因果推断与强化学习交叉领域的最新研究进展,并将现有方法划分为以下几类:因果表征学习、反事实策略优化、离线因果强化学习、因果迁移学习以及因果可解释性。通过这一结构化分析,我们总结了该领域面临的主要挑战,梳理了在实际应用中的经验性成功案例,并讨论了若干尚待解决的开放问题。最后,本文展望了未来的研究方向,强调了因果强化学习在构建鲁棒、具备良好泛化能力且可解释的人工智能系统方面的巨大潜力。
I. 引言(INTRODUCTION)
强化学习(Reinforcement Learning,RL)方法正在深刻地改变医疗、机器人、金融等众多领域,已成为推动传统机器学习模型性能迈向新高度的核心动力。然而,强化学习方法在实际应用中的落地仍然受到鲁棒性不足、可解释性欠缺以及泛化能力不可靠等问题的严重制约。 本文通过系统整合并分析因果推断与强化学习这一快速发展的交叉领域,为该方向做出了重要贡献。通过阐明因果思维如何缓解甚至克服传统强化学习的根本性挑战,本文为希望构建更加鲁棒、可解释且可信赖的人工智能系统的研究人员和实践者提供了重要的基础性资源。 除理论贡献外,本文还提供了丰富的实践资源,以加速因果强化学习研究的发展。我们引入了 11 个基准环境,专门用于隔离和评估多种因果挑战,包括混杂观测、伪相关、分布偏移以及隐藏的共同原因等问题,为社区提供了此前尚不存在的标准化测试平台。我们提出了 4 种因果强化学习算法(CausalPPO、CAE-PPO、PACE 和 ExplainableSCM),并给出了完整实现与代码,便于研究者在此基础上进一步拓展。此外,我们还设计了全面的评估协议,不仅衡量任务性能,还系统评估因果鲁棒性、迁移能力以及解释质量。 这些贡献共同构成了一个完整的实验框架,将理论概念与经验验证紧密结合,显著降低了新进入该领域研究者的入门门槛。 本文综述所凝练的洞见有望指导未来 AI 系统的理论发展与实际部署,推动自动化决策系统在可靠性、质量、可信度及社会接受度等方面的持续提升。
II. 背景与贡献(BACKGROUND AND CONTRIBUTIONS)
因果推理被广泛认为是人类智能与人工智能的核心组成部分,使智能体能够超越简单的关联模式,对世界进行解释、预测与干预。认知科学研究表明,人类在生命早期便开始形成对因果关系的理解,并利用这种理解在不确定条件下进行解释和决策 [1]–[4]。这种对因果结构进行表征与操控的能力,不仅使我们能够预测未来结果,还支持反事实推理——即思考在不同条件下“本可以发生什么”。 近年来,因果性在人工智能中的重要性愈发凸显,被视为实现泛化性强、鲁棒且可解释的决策机制的关键。“因果革命” [4] 明确指出,因果性是从统计模式识别迈向真正理解与推理的核心要素。近期的一项综述 [5] 进一步强调,因果推理为解决强化学习中的长期难题提供了有前景的路径,包括样本效率低、泛化能力不足以及可解释性差等问题。
A. 传统强化学习的局限性
尽管强化学习在游戏等模拟环境中取得了显著成功 [6], [7],其在真实世界环境中的广泛应用仍受到若干根本性挑战的制约。虽然在控制、机器人、金融和医疗等领域已出现一定成功案例 [8],但强化学习尚未在现实生产级应用中得到普遍部署。 传统强化学习算法高度依赖大规模交互数据,并且在脱离训练环境后往往难以泛化,其原因在于奖励函数通常受到训练过程中未被充分学习的外部因素影响。这些局限的根源在于:标准 RL 方法主要依赖经验中学习到的关联模式,而未能理解驱动环境动态变化的潜在因果机制 [9]。 在医疗、机器人和金融等高风险应用中,这种数据饥渴且脆弱的学习方式往往不可行甚至不安全 [10],同时由于缺乏可解释性,所得到的模型也难以被信任。例如,使用离策略数据训练的智能体可能会遭遇分布偏移或未观测混杂因素,从而导致性能退化或不安全行为。此外,传统深度强化学习策略通常呈现“黑箱”特性,给行为调试与系统信任建立带来极大困难 [11]。在缺乏环境因果模型的情况下,智能体极易学习到伪相关关系,进而导致泛化性能差,甚至产生不公平或不安全的决策结果 [12], [13]。
B. 因果性为何对强化学习至关重要
因果推断为解决传统强化学习内在局限性提供了一种系统而严谨的理论框架。通过建模环境中的因果结构,智能体能够识别哪些变量真正影响结果,并据此构建对分布偏移更具鲁棒性的策略 [14], [3]。例如,相较于将所有观测到的相关性视为同等重要,具备因果意识的智能体可以优先关注对奖励或状态转移具有真实因果影响的变量。 引入因果推理使强化学习智能体能够从被动观测走向主动干预,在 Pearl 提出的“因果阶梯”上,从关联层次跃迁至干预与反事实推理层次 [15], [4]。这使得智能体能够回答诸如“如果采取了不同的动作,会发生什么?”这样的反事实问题,从而显著提升信用分配与探索效率 [16]。此外,因果模型还能通过引导信息性干预和利用因果不变性支持跨任务迁移,从而提升样本效率 [17], [18];同时,基于因果依赖关系而非黑箱相关性的解释,也显著增强了系统的可解释性 [11]。
C. 综述目标与范围
本文综述的核心目标是对因果推断与强化学习交叉领域的最新研究进展进行系统性整合与批判性分析,具体包括以下五个方面: 澄清概念联系:系统梳理因果推断中的核心概念(如结构因果模型、反事实推理、干预与混杂)与强化学习基本要素(如状态表示、策略、价值估计与决策过程)之间的对应关系。 方法分类:提出一个全面而结构化的分类体系,清晰区分因果表征学习、因果策略优化、反事实强化学习、离线因果强化学习、因果迁移学习以及因果可解释性方法。 关键技术挑战:突出因果推断与强化学习融合过程中面临的主要理论、方法与经验挑战,重点关注可扩展性、分布偏移鲁棒性、因果结构识别以及计算可行性。 经验证据与应用:总结并评估因果强化学习在机器人、医疗、自动驾驶、教育与金融等领域中的实证研究成果,讨论其成功经验、局限性与实践意义。 未来研究方向:识别开放研究问题,并为未来研究提供指导性建议,指出在方法创新与实际应用方面可能产生重大突破的方向。 为保持讨论的聚焦性,本文主要涵盖近五年来明确将因果推断与强化学习相结合的研究工作;仅泛泛提及因果性、但未引入具体因果建模或因果推理机制的方法不在本文讨论范围之内。此外,本文假设读者已具备强化学习与因果推断的基础知识,仅对相关背景作简要回顾,重点聚焦二者的交叉融合。
D. 综述贡献
随着因果强化学习(CRL)逐渐成为一个关键研究方向,亟需对该领域进行系统、前沿的综合梳理。本文致力于弥合因果理论与强化学习实践之间的鸿沟,通过以下贡献推动该领域发展: * 全面的分类体系:将因果强化学习研究划分为五个核心方向:(i)因果表征学习,(ii)反事实策略学习,(iii)离线因果强化学习,(iv)迁移学习与泛化,以及(v)可解释性。该分类覆盖了 CRL 中最活跃、最具影响力的研究子领域。 * 实践相关性分析:系统阐述上述各方向为何对构建鲁棒、可泛化且可信赖的强化学习系统至关重要:因果表征学习应对伪相关问题;反事实策略学习支持“假设性”推理与更优信用分配;离线因果 RL 实现从混杂数据中安全学习;迁移学习利用因果不变性;可解释性提供透明的因果解释。 * 基准环境:提出 11 个因果强化学习评测环境,均基于 Gymnasium 封装 [19],用于系统评估因果挑战,包括: – Study A(第 VII 节):SpuriousFeatureWrapper,包含 3 种 CartPole 物理变体; – Study B(第 VII 节):4 个混杂环境——ConfoundedBandit、BanditHard、ConfoundedFrozenLake、ConfoundedBlackjack; – Study C(第 VII 节):3 个混杂上下文 bandit——ConfoundedDosage、ConfoundedPricing、ConfoundedTargeting; – Study D(第 VII 节):用于视觉分布偏移的 VisualDistractionWrapper。 * 因果强化学习算法及实证验证:提出并验证了 4 种 CRL 算法: – CausalPPO(算法 2):通过结构性忽略伪特征,使 PPO 对伪相关具备鲁棒性,实现 99.8%–100% 的性能差距缩减; – CAE-PPO(算法 3):基于轨迹的混杂因子推断进行反事实优势估计,弥合 101% 的 Standard-Oracle 差距; – PACE(算法 4):代理变量校正的离线因果估计,在混杂条件下实现 65% 的奖励提升; – ExplainableSCM(算法 5):基于结构因果模型的因果解释方法,在接近完美的动态预测下,提供稳定性提升 82% 的解释结果。 * 前沿覆盖性:系统纳入最新研究进展,重点突出离线因果 RL 与因果迁移学习中的新方法、新算法、新环境及其应用实证,区别于以往综述。 * 可复现研究:所有代码、环境、算法与实验配置均已开源,支持完整复现实验结果,为未来 CRL 研究提供坚实基础。