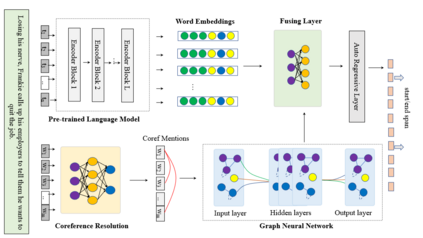
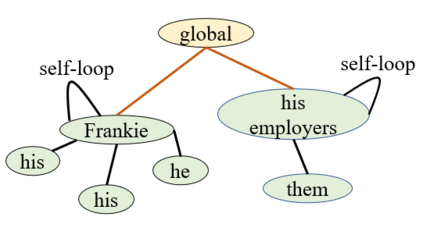
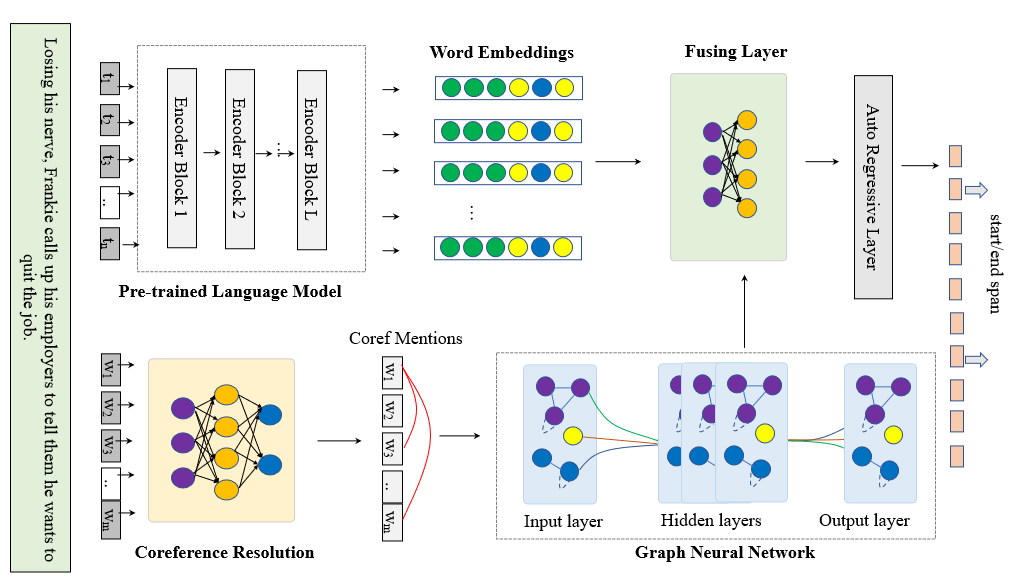
Machine reading comprehension is a heavily-studied research and test field for evaluating new pre-trained models and fine-tuning strategies, and recent studies have enriched the pre-trained models with syntactic, semantic and other linguistic information to improve the performance of the model. In this paper, we imitated the human's reading process in connecting the anaphoric expressions and explicitly leverage the coreference information to enhance the word embeddings from the pre-trained model, in order to highlight the coreference mentions that must be identified for coreference-intensive question answering in QUOREF, a relatively new dataset that is specifically designed to evaluate the coreference-related performance of a model. We used an additional BERT layer to focus on the coreference mentions, and a Relational Graph Convolutional Network to model the coreference relations. We demonstrated that the explicit incorporation of the coreference information in fine-tuning stage performed better than the incorporation of the coreference information in training a pre-trained language models.
翻译:机器阅读理解是评价新的预先培训的模型和微调战略的密集研究和测试领域,最近的研究用综合、语义和其他语言信息丰富了经过培训的模型,以改进模型的性能。在本文中,我们模仿人类阅读过程,将厌光表达方式连接起来,并明确利用共同参考信息来加强从经过培训的模式中嵌入的词,以突出在QUOREF中为共同参考密集问题解答而必须确定的共同参考提及,这是一个较新的数据集,专门设计用于评价一个模型的共参考相关性能。我们利用额外的BERT层来侧重于共同引用,并用关联图动网络来模拟共同参照关系。我们证明,在微调阶段明确纳入参考信息比在培训预先培训的语言模型时纳入共同参考信息要好。