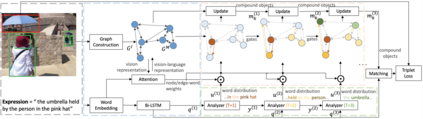
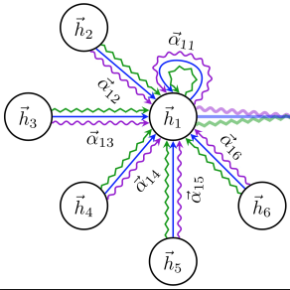
Referring expression comprehension aims to locate the object instance described by a natural language referring expression in an image. This task is compositional and inherently requires visual reasoning on top of the relationships among the objects in the image. Meanwhile, the visual reasoning process is guided by the linguistic structure of the referring expression. However, existing approaches treat the objects in isolation or only explore the first-order relationships between objects without being aligned with the potential complexity of the expression. Thus it is hard for them to adapt to the grounding of complex referring expressions. In this paper, we explore the problem of referring expression comprehension from the perspective of language-driven visual reasoning, and propose a dynamic graph attention network to perform multi-step reasoning by modeling both the relationships among the objects in the image and the linguistic structure of the expression. In particular, we construct a graph for the image with the nodes and edges corresponding to the objects and their relationships respectively, propose a differential analyzer to predict a language-guided visual reasoning process, and perform stepwise reasoning on top of the graph to update the compound object representation at every node. Experimental results demonstrate that the proposed method can not only significantly surpass all existing state-of-the-art algorithms across three common benchmark datasets, but also generate interpretable visual evidences for stepwisely locating the objects referred to in complex language descriptions.
翻译:引用表达式理解的目的是要定位自然语言引用图像表达表达式所描述的对象实例。 此项任务是构成性的, 必然需要在图像中对象之间的关系之上进行视觉推理。 同时, 视觉推理过程以参考表达式的语言结构为指导。 但是, 现有的方法孤立地对待对象, 或只是探索对象之间的一阶关系, 而不会与表达式的潜在复杂性相匹配 。 因此, 它们很难适应复杂引用表达式的基础化 。 在本文中, 我们探索从语言驱动视觉推理的角度来引用表达式理解的问题, 并提议一个动态图形关注网络, 通过模拟图像对象之间的关系和表达式的语言结构来进行多步推理。 特别是, 我们用与对象及其关系相对应的节点和边缘来构建图像的图表。 提议一个差异分析器, 以预测语言引导的视觉推理过程, 并在图表顶端进行阶推理推理推理, 以更新每个节点的复合对象的表达式表达式表达式。 实验结果表明, 拟议的方法不仅大大超过所有现有图像对象之间的关系, 并且大大超越了所有可移动的图像缩缩略式的图表 。