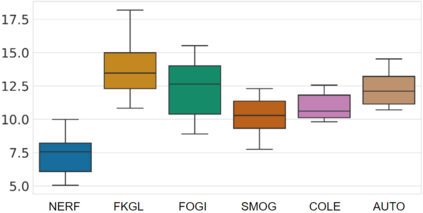
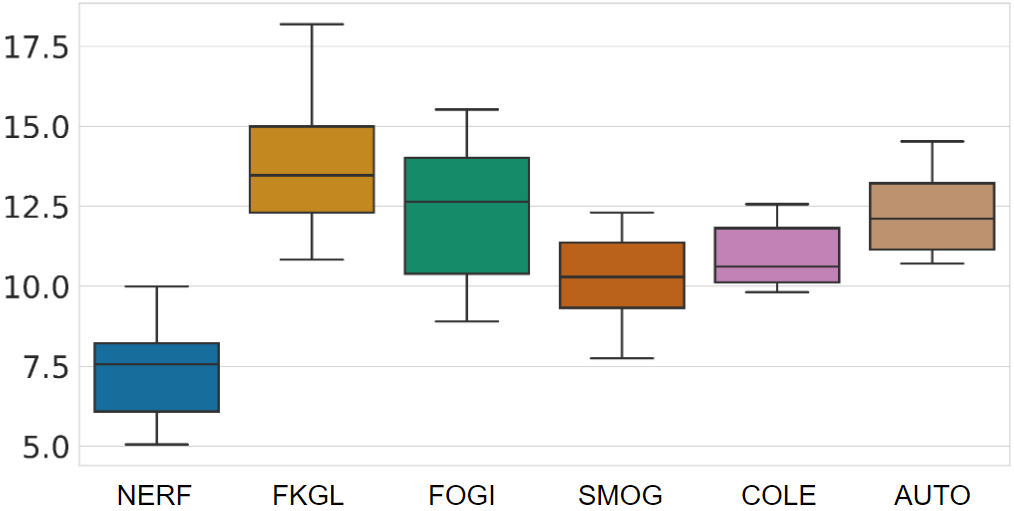
Traditional English readability formulas, or equations, were largely developed in the 20th century. Nonetheless, many researchers still rely on them for various NLP applications. This phenomenon is presumably due to the convenience and straightforwardness of readability formulas. In this work, we contribute to the NLP community by 1. introducing New English Readability Formula (NERF), 2. recalibrating the coefficients of old readability formulas (Flesch-Kincaid Grade Level, Fog Index, SMOG Index, Coleman-Liau Index, and Automated Readability Index), 3. evaluating the readability formulas, for use in text simplification studies and medical texts, and 4. developing a Python-based program for the wide application to various NLP projects.
翻译:传统的英语可读性公式(或方程式)在20世纪已基本发展,然而,许多研究人员仍依赖这些公式来应用国家可读性指标,这种现象大概是由于可读性公式的方便性和直接性。在这项工作中,我们向国家可读性方案社区作出贡献,方法是1. 采用新的英语可读性公式(NERF),2. 重新调整旧可读性公式的系数(Flesch-Kincaid 等级、雾指数、SOMG指数、Coleman-Liau指数和自动可读性指数)、3. 评估可读性公式,用于文字简化研究和医学文本,4. 开发一个基于Python的方案,广泛应用于国家可读性指标项目。