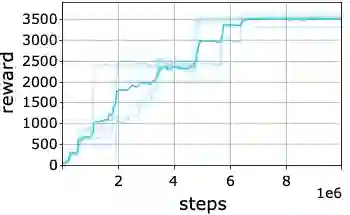
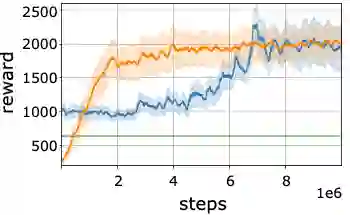
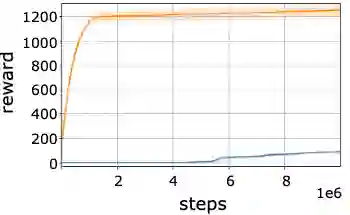
In recent years, there has been significant progress in applying deep reinforcement learning (RL) for solving challenging problems across a wide variety of domains. Nevertheless, convergence of various methods has been shown to suffer from inconsistencies, due to algorithmic instability and variance, as well as stochasticity in the benchmark environments. Particularly, despite the fact that the agent's performance may be improving on average, it may abruptly deteriorate at late stages of training. In this work, we study methods for enhancing the agent's learning process, by providing conservative updates with respect to either the obtained history or a reference benchmark policy. Our method, termed EVEREST, obtains high confidence improvements via confidence bounds of a reference policy. Through extensive empirical analysis we demonstrate the benefit of our approach in terms of both performance and stabilization, with significant improvements in continuous control and Atari benchmarks.
翻译:近年来,在应用深入强化学习(RL)解决各个领域的棘手问题方面取得了重大进展,然而,由于算法不稳定和差异,以及基准环境的随机性,各种方法的趋同都存在不一致,特别是,尽管该代理人的性能可能平均在改善,但在培训的后期阶段可能突然恶化。在这项工作中,我们研究加强该代理人的学习过程的方法,提供关于所获得历史或参考基准政策的保守更新。我们称为EWEEEST的方法通过参照政策的信任界限获得了高度的信心改善。通过广泛的实证分析,我们展示了我们在业绩和稳定方面的做法的好处,在持续控制和Atari基准方面有了重大改进。