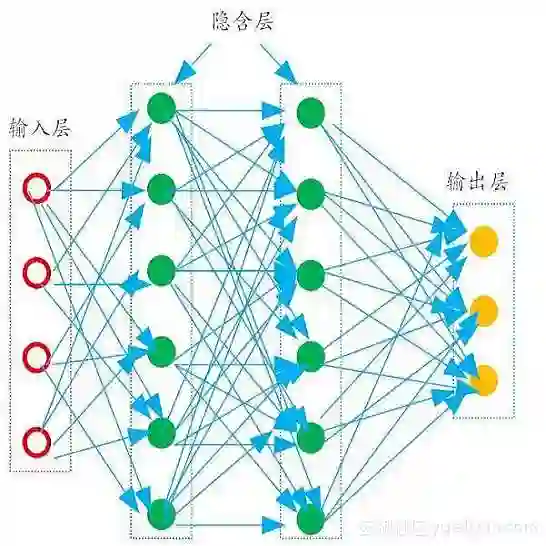
To classify images based on their content is one of the most studied topics in the field of computer vision. Nowadays, this problem can be addressed using modern techniques such as Convolutional Neural Networks (CNN), but over the years different classical methods have been developed. In this report, we implement an image classifier using both classic computer vision and deep learning techniques. Specifically, we study the performance of a Bag of Visual Words classifier using Support Vector Machines, a Multilayer Perceptron, an existing architecture named InceptionV3 and our own CNN, TinyNet, designed from scratch. We evaluate each of the cases in terms of accuracy and loss, and we obtain results that vary between 0.6 and 0.96 depending on the model and configuration used.
翻译:根据内容对图像进行分类是计算机视觉领域研究最多的课题之一。如今,这个问题可以用现代技术,如进化神经网络(CNN)来解决,但多年来已经开发出不同的古典方法。在本报告中,我们使用经典计算机视觉和深层学习技术实施图像分类方法。具体地说,我们用支持矢量机(多层感应器)研究一袋视觉文字分类器的性能,一个名为“感应V3”的现有结构,以及我们从零开始设计的CNN(TinyNet),我们从准确性和损失角度对每个案例进行了评估,我们根据所使用的模型和配置获得的结果介于0.6和0.96之间。