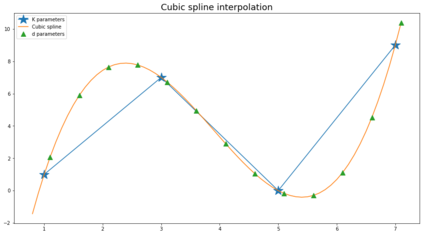
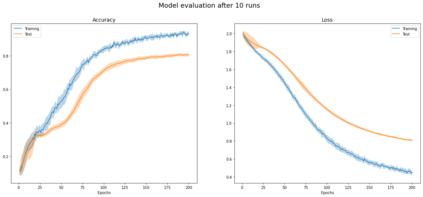
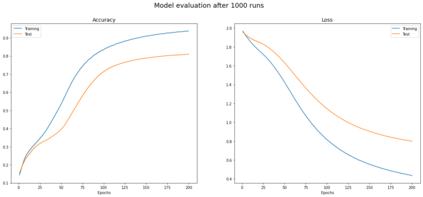
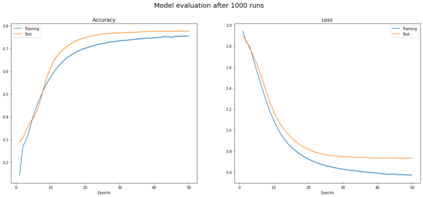
Graph Convolutional Networks (GCNs) have been shown to be a powerful concept that has been successfully applied to a large variety of tasks across many domains over the past years. In this work we study the theory that paved the way to the definition of GCN, including related parts of classical graph theory. We also discuss and experimentally demonstrate key properties and limitations of GCNs such as those caused by the statistical dependency of samples, introduced by the edges of the graph, which causes the estimates of the full gradient to be biased. Another limitation we discuss is the negative impact of minibatch sampling on the model performance. As a consequence, during parameter update, gradients are computed on the whole dataset, undermining scalability to large graphs. To account for this, we research alternative methods which allow to safely learn good parameters while sampling only a subset of data per iteration. We reproduce the results reported in the work of Kipf et al. and propose an implementation inspired to SIGN, which is a sampling-free minibatch method. Eventually we compare the two implementations on a benchmark dataset, proving that they are comparable in terms of prediction accuracy for the task of semi-supervised node classification.
翻译:在过去几年中,我们研究的理论为GCN的定义铺平了道路,包括古典图形理论的相关部分。我们还讨论并实验性地展示了GCN的关键属性和局限性,如样本统计依赖性造成的、由图边缘引入的、导致整个梯度估计偏差的GCN的关键属性和局限性。我们讨论的另一个限制是微型批量抽样对模型性能的负面影响。结果,在更新参数的过程中,在整个数据集上计算梯度,从而破坏大图的可缩缩度。为此,我们研究能够安全地学习良好参数的替代方法,同时仅按其次取样一组数据。我们抄录了基夫等人的工作报告的结果,并提出了受SIGT启发的执行办法,这是一种无抽样小型批量法。最后,我们比较了基准数据集上的两个执行办法,证明它们在预测半超级分类的准确性方面是可比的。