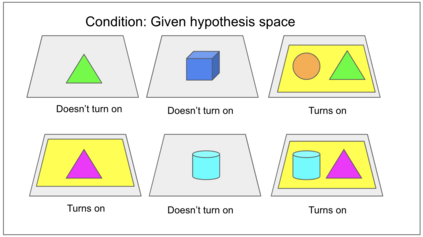
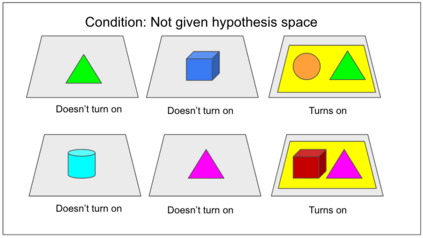
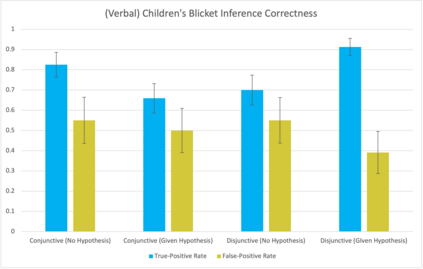
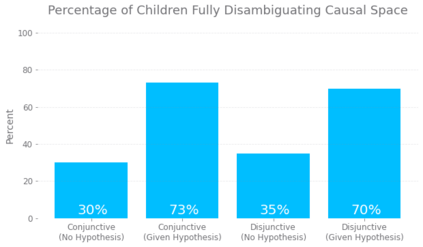
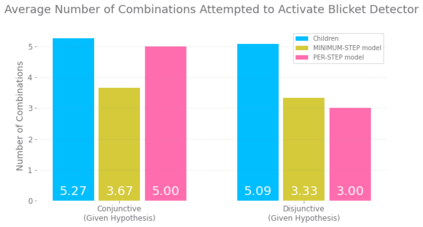
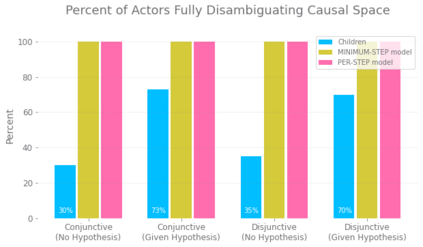
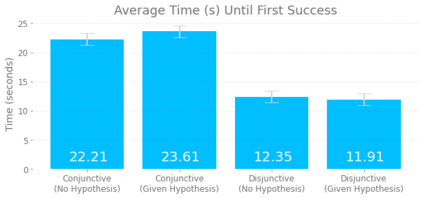
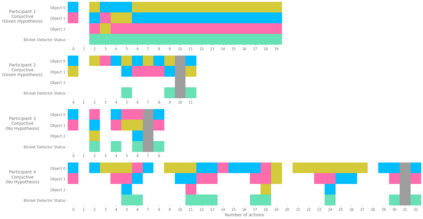Despite recent progress in reinforcement learning (RL), RL algorithms for exploration still remain an active area of research. Existing methods often focus on state-based metrics, which do not consider the underlying causal structures of the environment, and while recent research has begun to explore RL environments for causal learning, these environments primarily leverage causal information through causal inference or induction rather than exploration. In contrast, human children - some of the most proficient explorers - have been shown to use causal information to great benefit. In this work, we introduce a novel RL environment designed with a controllable causal structure, which allows us to evaluate exploration strategies used by both agents and children in a unified environment. In addition, through experimentation on both computation models and children, we demonstrate that there are significant differences between information-gain optimal RL exploration in causal environments and the exploration of children in the same environments. We conclude with a discussion of how these findings may inspire new directions of research into efficient exploration and disambiguation of causal structures for RL algorithms.
翻译:尽管在强化学习(RL)方面最近取得了进展,但勘探的RL算法仍是一个积极的研究领域,现有方法往往侧重于基于国家的指标,其中不考虑环境的内在因果结构,虽然最近的研究已经开始探索RL环境,以便进行因果学习,但这些环境主要通过因果推断或诱导而不是勘探来利用因果信息。相反,人类儿童(一些最熟练的探索者)被证明利用因果信息大有裨益。在这项工作中,我们引入了一个具有可控制因果结构的新颖的RL环境,使我们能够评价代理人和儿童在统一环境中使用的勘探战略。此外,通过对计算模型和儿童进行实验,我们证明在因果环境中最佳的RL探索与对同一环境中的儿童的探索之间存在巨大差异。我们最后讨论了这些发现如何激发新的研究方向,以便有效探索和模糊RL算法的因果结构。