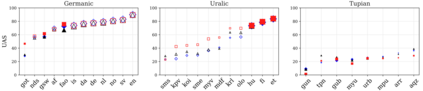
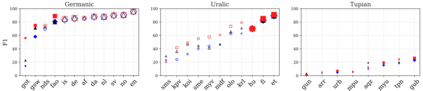
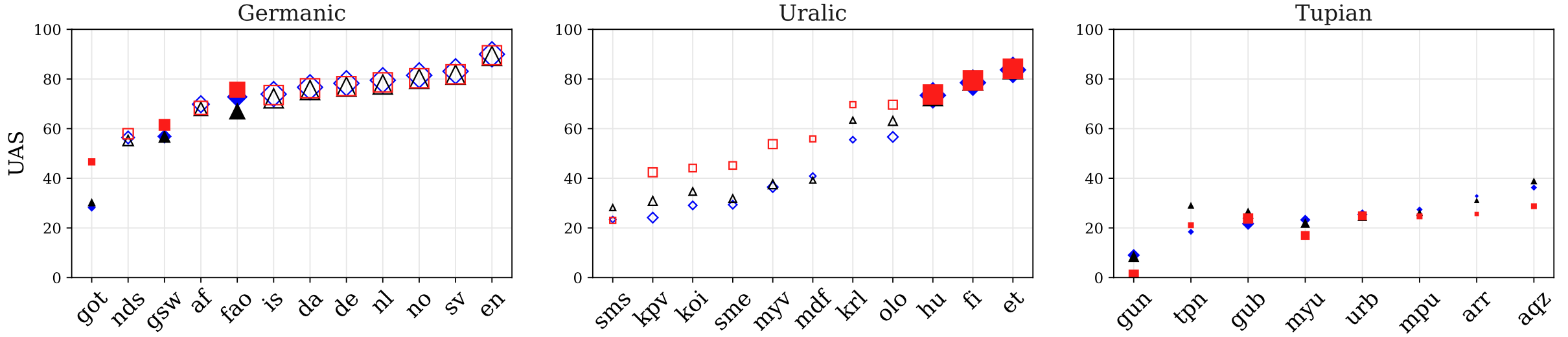
Large pretrained multilingual models, trained on dozens of languages, have delivered promising results due to cross-lingual learning capabilities on variety of language tasks. Further adapting these models to specific languages, especially ones unseen during pre-training, is an important goal towards expanding the coverage of language technologies. In this study, we show how we can use language phylogenetic information to improve cross-lingual transfer leveraging closely related languages in a structured, linguistically-informed manner. We perform adapter-based training on languages from diverse language families (Germanic, Uralic, Tupian, Uto-Aztecan) and evaluate on both syntactic and semantic tasks, obtaining more than 20% relative performance improvements over strong commonly used baselines, especially on languages unseen during pre-training.
翻译:受过数十种语言培训的大型预先培训的多语种模式,由于在各种语言任务上具有跨语言学习能力,已经取得了令人乐观的成果。进一步将这些模式适应特定语言,特别是培训前所未见的语言,是扩大语言技术覆盖面的一个重要目标。在这项研究中,我们展示了我们如何利用语言生理遗传信息,以结构化、语言知情的方式利用密切关联的语言,改进跨语言转让。我们开展了基于适应者的不同语言家庭语言(德语、乌拉利奇语、图皮安语、乌托阿兹泰肯语)的培训,并评估了合成和语义任务,在常用的强基线上取得了超过20%的相对绩效改进,特别是在培训前未见的语言上。