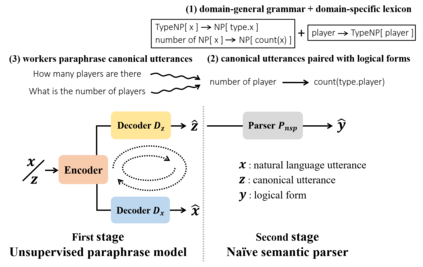
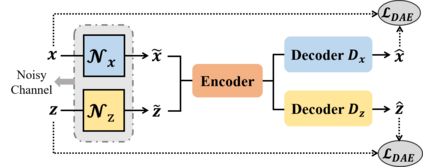
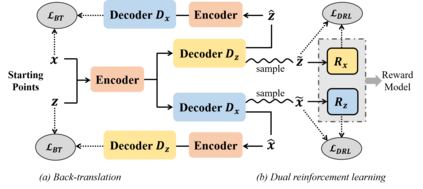
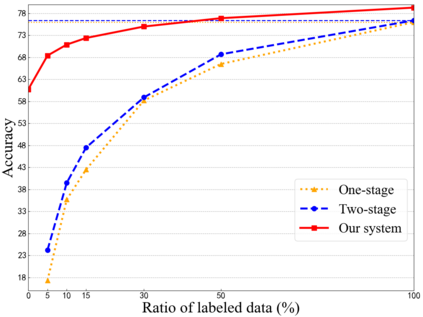
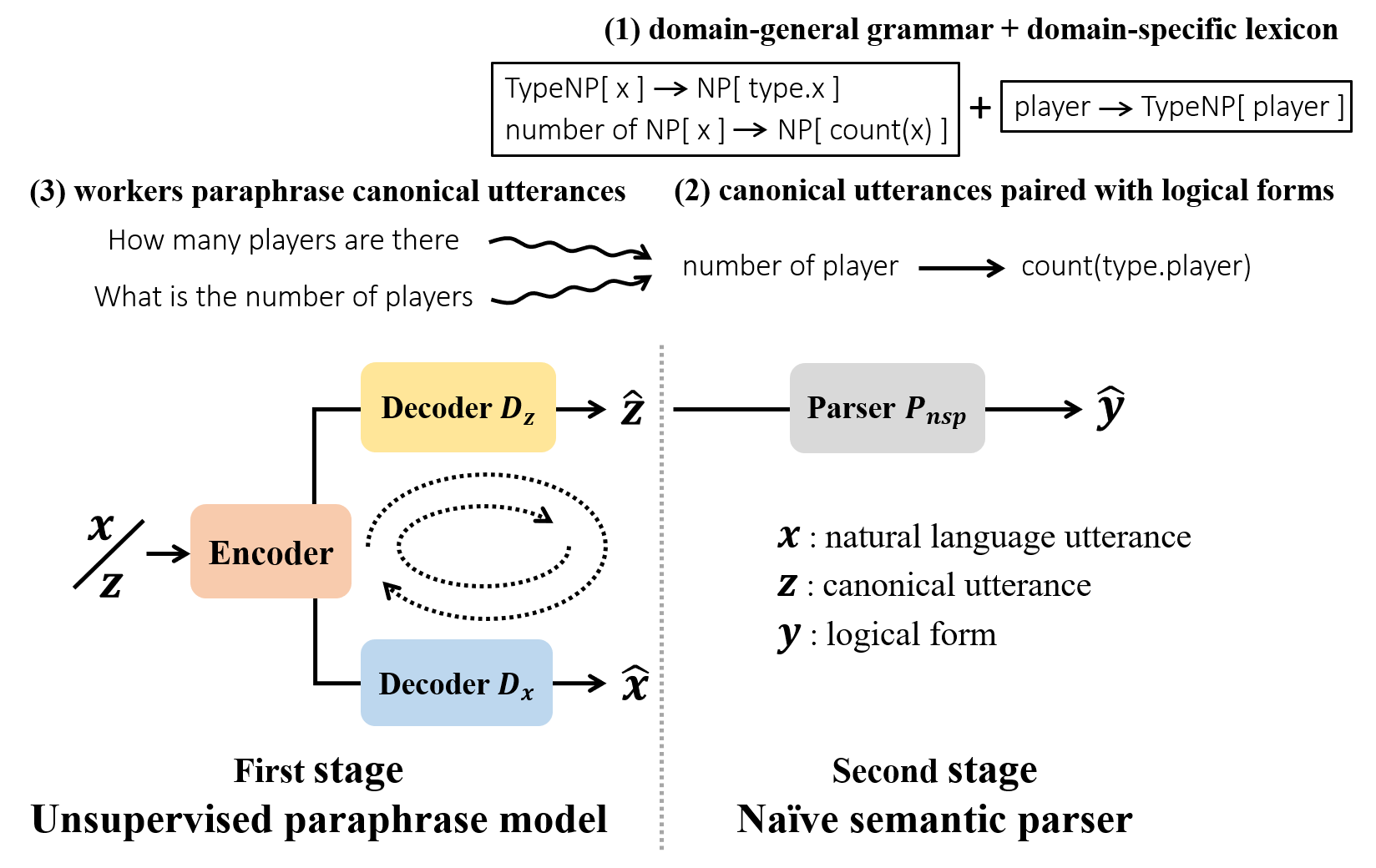
One daunting problem for semantic parsing is the scarcity of annotation. Aiming to reduce nontrivial human labor, we propose a two-stage semantic parsing framework, where the first stage utilizes an unsupervised paraphrase model to convert an unlabeled natural language utterance into the canonical utterance. The downstream naive semantic parser accepts the intermediate output and returns the target logical form. Furthermore, the entire training process is split into two phases: pre-training and cycle learning. Three tailored self-supervised tasks are introduced throughout training to activate the unsupervised paraphrase model. Experimental results on benchmarks Overnight and GeoGranno demonstrate that our framework is effective and compatible with supervised training.
翻译:语义解析的一个令人生畏的问题是缺乏批注。 为了减少非技术性的人类劳动,我们提议了一个两阶段语义解析框架, 第一阶段使用一个不受监督的参数模型, 将未贴标签的自然语言的发音转换为发音。 下游天文语义分析师接受中间输出并返回目标逻辑形式。 此外, 整个培训过程被分为两个阶段: 培训前和周期学习。 在整个培训过程中引入了三个定制的自我监督任务, 以激活未经监督的参数模型。 夜间基准和GeoGranno的实验结果表明,我们的框架是有效的,并且与监督的培训相容的。