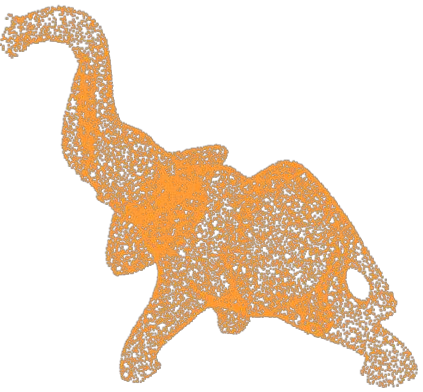
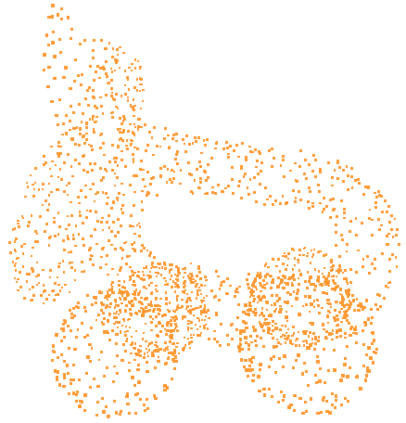
Point clouds obtained from 3D sensors are usually sparse. Existing methods mainly focus on upsampling sparse point clouds in a supervised manner by using dense ground truth point clouds. In this paper, we propose a self-supervised point cloud upsampling network (SSPU-Net) to generate dense point clouds without using ground truth. To achieve this, we exploit the consistency between the input sparse point cloud and generated dense point cloud for the shapes and rendered images. Specifically, we first propose a neighbor expansion unit (NEU) to upsample the sparse point clouds, where the local geometric structures of the sparse point clouds are exploited to learn weights for point interpolation. Then, we develop a differentiable point cloud rendering unit (DRU) as an end-to-end module in our network to render the point cloud into multi-view images. Finally, we formulate a shape-consistent loss and an image-consistent loss to train the network so that the shapes of the sparse and dense point clouds are as consistent as possible. Extensive results on the CAD and scanned datasets demonstrate that our method can achieve impressive results in a self-supervised manner. Code is available at https://github.com/fpthink/SSPU-Net.
翻译:从 3D 传感器获取的点云通常很少。 现有方法主要侧重于通过使用密集的地面真象点云来以监督的方式对稀有点云进行取样。 在本文中, 我们提议建立一个自我监督的点云取样网络( SSPU- Net), 以便在不使用地面真象的情况下生成密度点云。 为此, 我们利用输入的点云之间的一致性, 并为形状和图像生成生成密度点云。 具体地说, 我们首先提议建立一个邻居扩大单位( NEU) 来对稀有点云进行取样, 以便利用稀有点云的本地几何结构来学习点内插的重量。 然后, 我们开发了一个不同的点云传输单位( DRU ), 作为我们网络中的端对端模块, 将点云变成多视图图像。 最后, 我们设计了一个形状相容损失和图像相容的损失来训练网络, 以使稀薄和稠密的云的形状尽可能一致。 CADAD和扫描数据集的广泛结果显示, 我们的方法可以实现令人印象深刻的自我/ CD/ 。