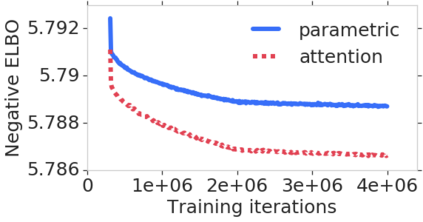
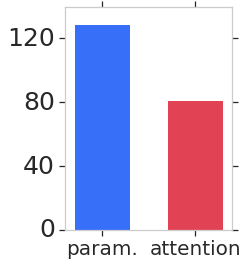
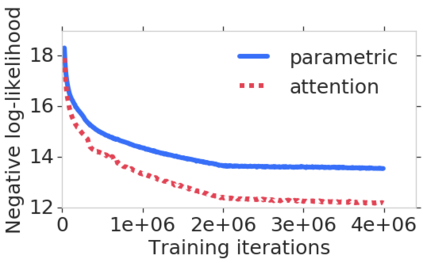
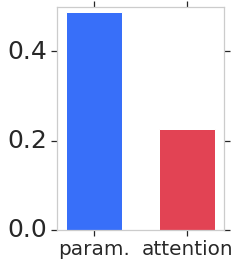
We consider learning based methods for visual localization that do not require the construction of explicit maps in the form of point clouds or voxels. The goal is to learn an implicit representation of the environment at a higher, more abstract level. We propose to use a generative approach based on Generative Query Networks (GQNs, Eslami et al. 2018), asking the following questions: 1) Can GQN capture more complex scenes than those it was originally demonstrated on? 2) Can GQN be used for localization in those scenes? To study this approach we consider procedurally generated Minecraft worlds, for which we can generate images of complex 3D scenes along with camera pose coordinates. We first show that GQNs, enhanced with a novel attention mechanism can capture the structure of 3D scenes in Minecraft, as evidenced by their samples. We then apply the models to the localization problem, comparing the results to a discriminative baseline, and comparing the ways each approach captures the task uncertainty.
翻译:我们考虑学习基于视觉定位的方法,这些方法不需要以点云或氧化物的形式绘制清晰的地图。目标是在更高、更抽象的层次上学习对环境的隐含描述。我们提议采用基于创世纪查询网络(GQNs, Eslami等人, 2018年)的基因化方法,提出以下问题:(1) GQN能否捕捉比最初展示的场景更复杂的场景?(2) GQN能否用于这些场景的本地化?为了研究这一方法,我们考虑在程序上生成的地雷手工艺世界,我们可以制作复杂的3D场景的图像,同时制作照相机姿势坐标。我们首先展示,通过新的关注机制加以强化的GQNs可以捕捉3D场景的结构,如它们的样品所证明的那样。然后我们将这些模型应用于本地化问题,将结果与歧视基线进行比较,并将每种方法捕捉任务不确定性的方法进行比较。