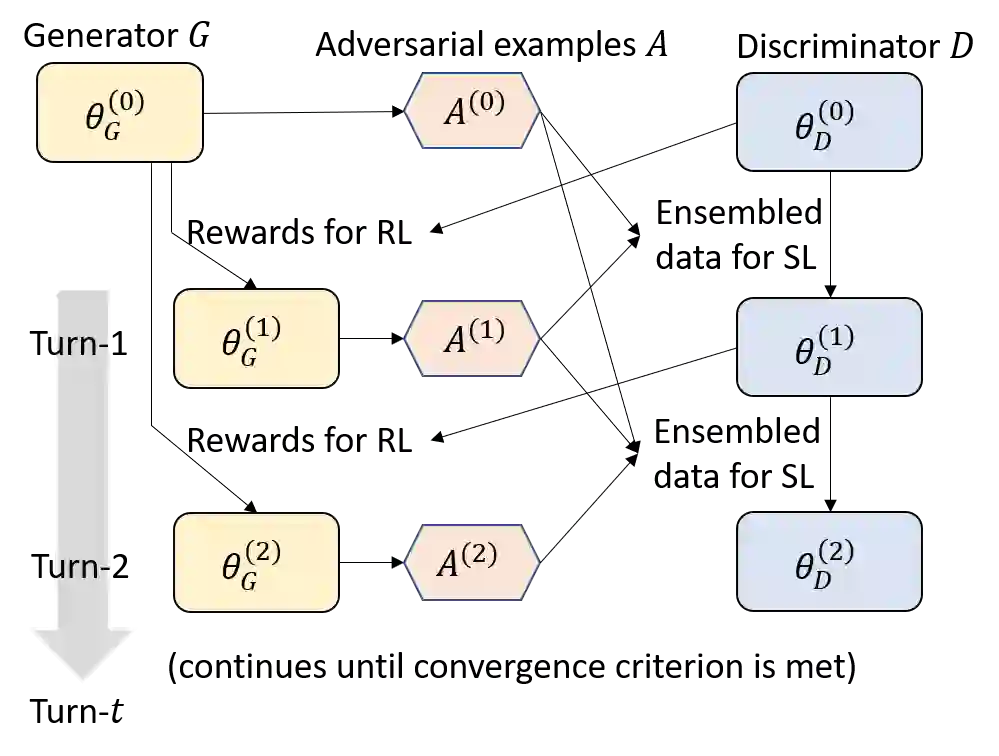
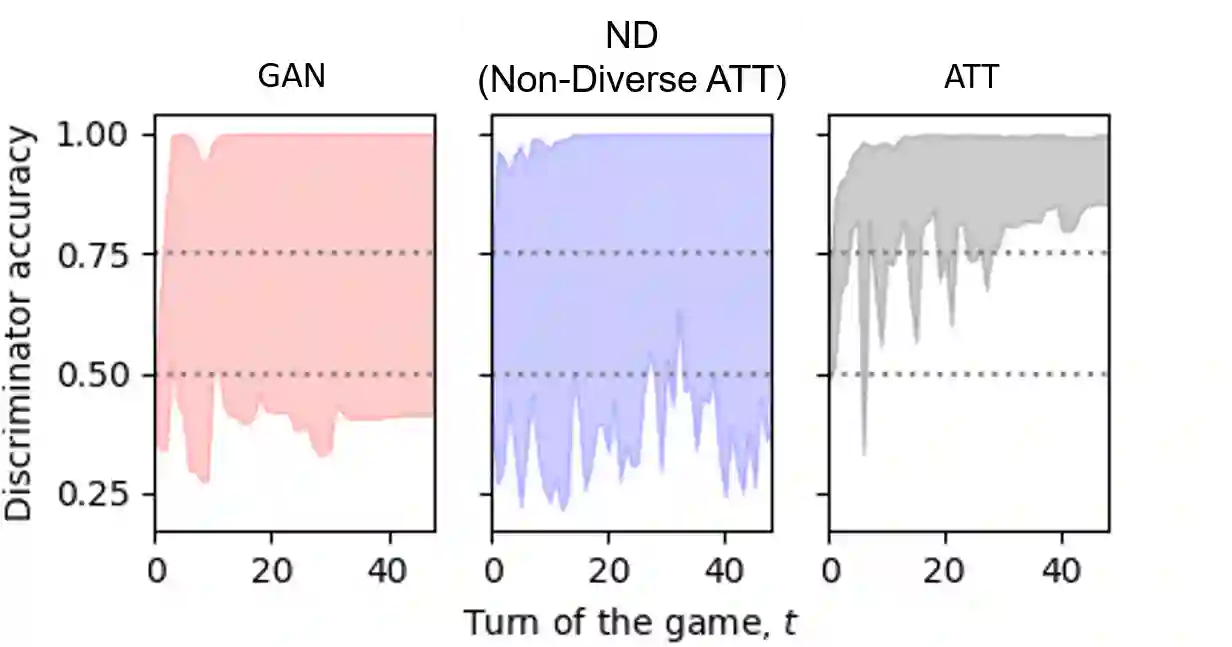
The design of better automated dialogue evaluation metrics offers the potential of accelerate evaluation research on conversational AI. However, existing trainable dialogue evaluation models are generally restricted to classifiers trained in a purely supervised manner, which suffer a significant risk from adversarial attacking (e.g., a nonsensical response that enjoys a high classification score). To alleviate this risk, we propose an adversarial training approach to learn a robust model, ATT (Adversarial Turing Test), that discriminates machine-generated responses from human-written replies. In contrast to previous perturbation-based methods, our discriminator is trained by iteratively generating unrestricted and diverse adversarial examples using reinforcement learning. The key benefit of this unrestricted adversarial training approach is allowing the discriminator to improve robustness in an iterative attack-defense game. Our discriminator shows high accuracy on strong attackers including DialoGPT and GPT-3.
翻译:设计更好的自动对话评价衡量标准可以加快对对话性对话的评价研究,但是,现有的可培训的对话评价模式一般限于以纯监督方式培训的分类人员,他们受到对抗性攻击的极大风险(例如,非敏感反应,享有很高的分类分),为了减轻这种风险,我们提议采用对抗性培训方法学习一种强健的模式,即ATT(反向图灵测试),这种模式区分机器产生的与人文答复的反应。与以往以扰动为基础的方法不同,我们的歧视者通过利用强化学习迭代产生不受限制和多样的对抗性例子接受培训。这种不受限制的对抗性培训方法的主要好处是允许歧视者在迭接的攻击性防御性游戏中提高稳健性。我们的歧视者对强攻击者(包括DialoGPT和GPT-3)表现出很高的准确性。