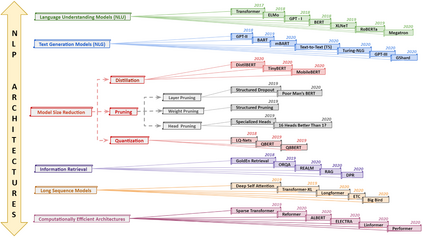
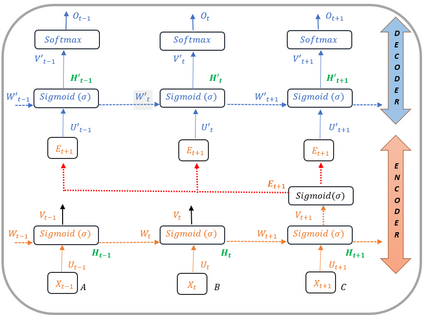
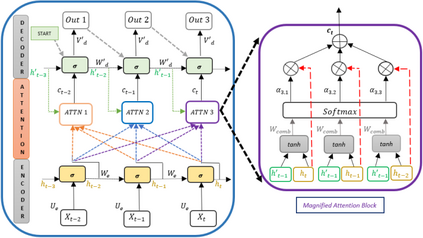
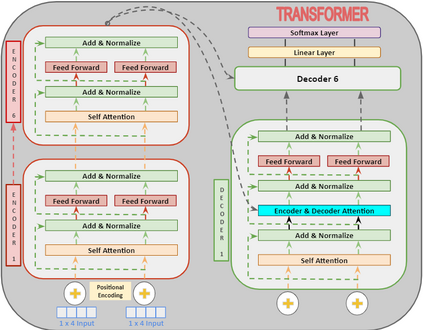
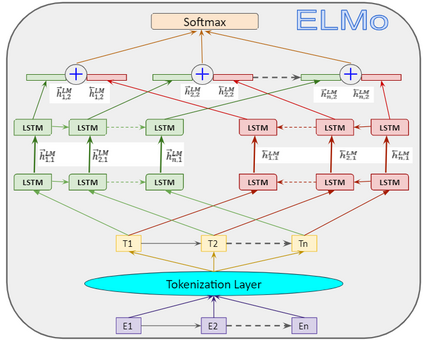
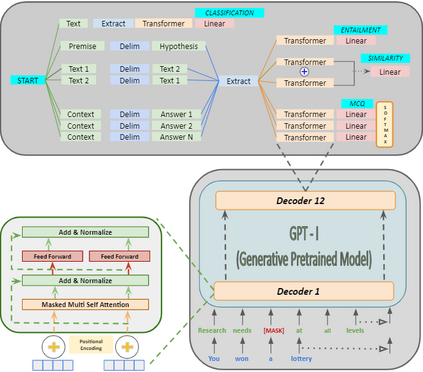
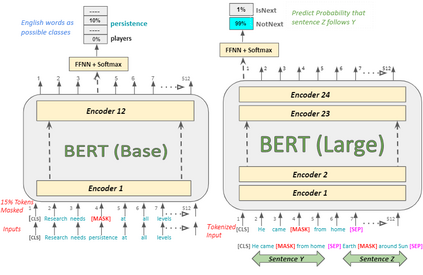
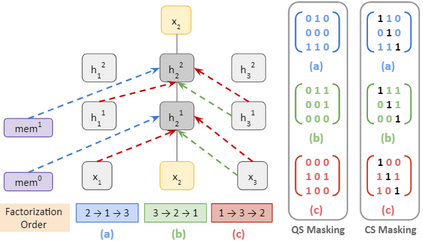
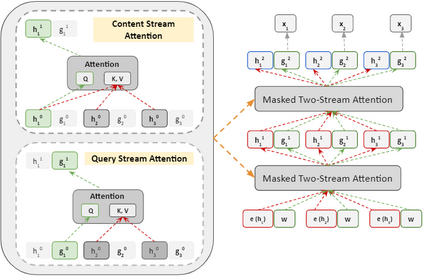
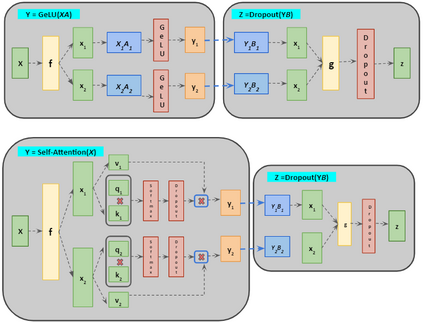
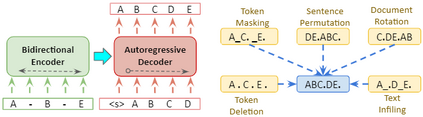
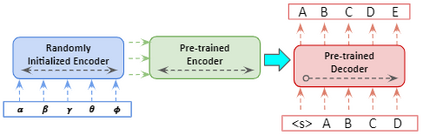
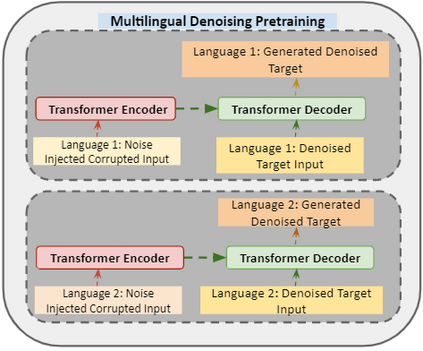
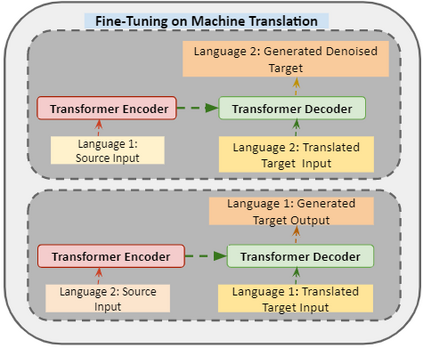
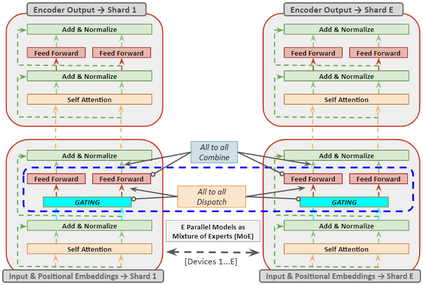
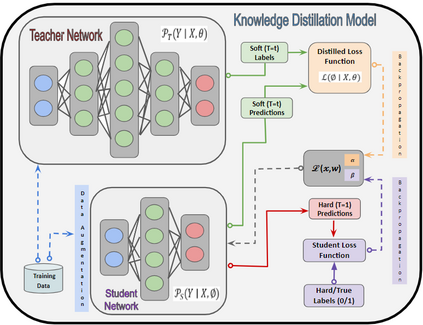
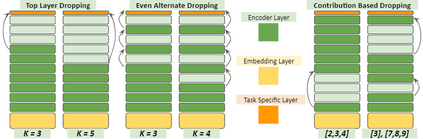
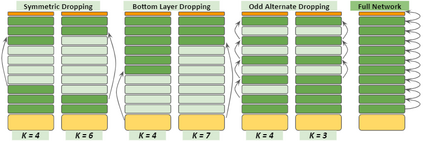
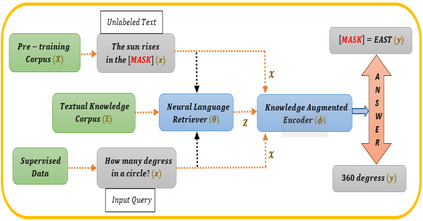
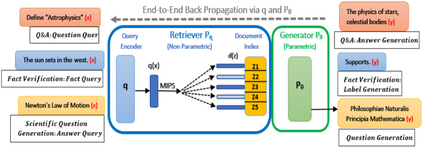
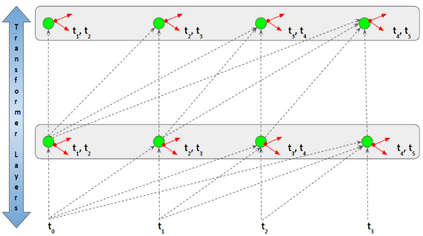
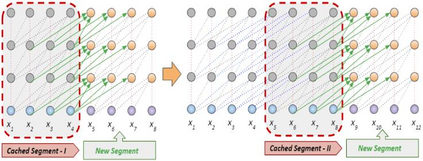
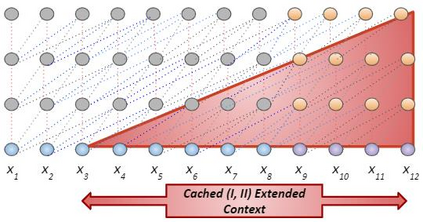
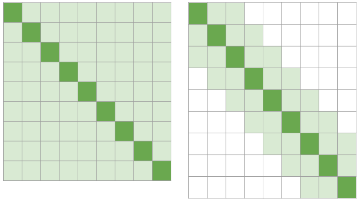
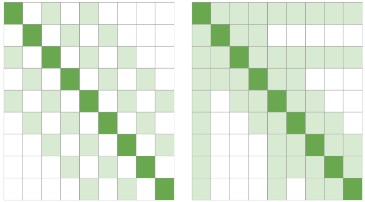
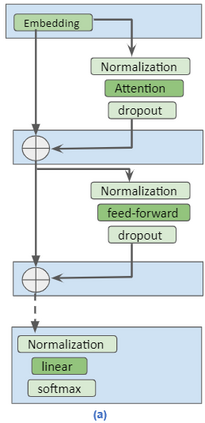
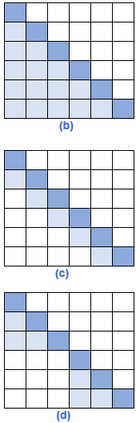
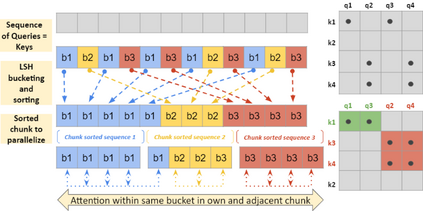
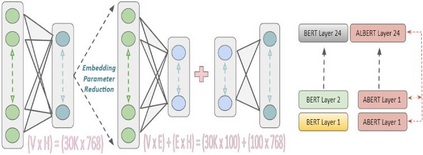
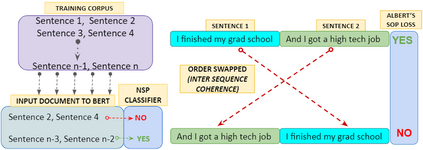
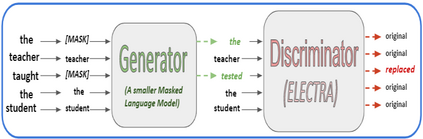
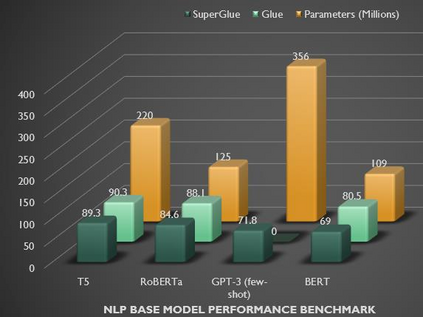
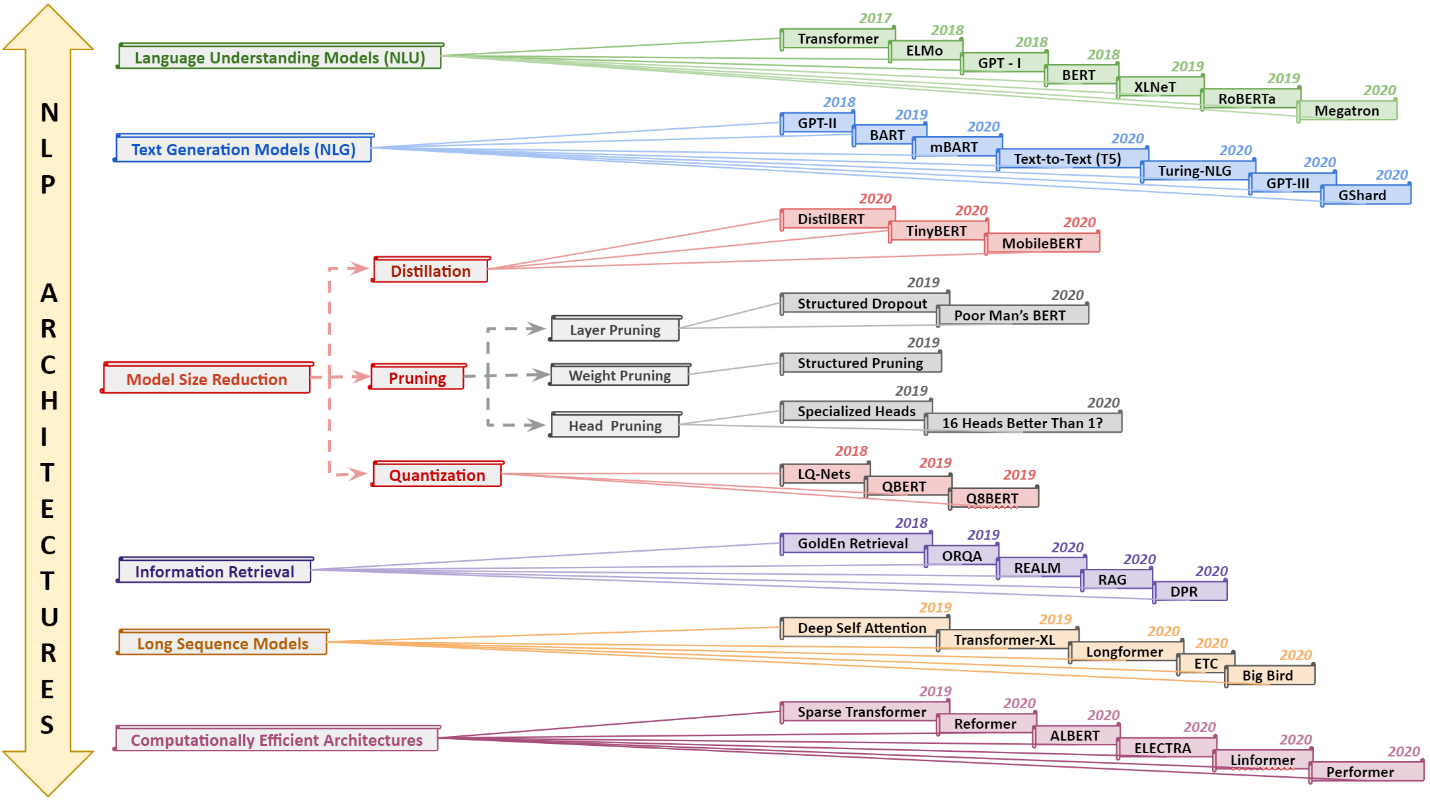
In recent years, Natural Language Processing (NLP) models have achieved phenomenal success in linguistic and semantic tasks like text classification, machine translation, cognitive dialogue systems, information retrieval via Natural Language Understanding (NLU), and Natural Language Generation (NLG). This feat is primarily attributed due to the seminal Transformer architecture, leading to designs such as BERT, GPT (I, II, III), etc. Although these large-size models have achieved unprecedented performances, they come at high computational costs. Consequently, some of the recent NLP architectures have utilized concepts of transfer learning, pruning, quantization, and knowledge distillation to achieve moderate model sizes while keeping nearly similar performances as achieved by their predecessors. Additionally, to mitigate the data size challenge raised by language models from a knowledge extraction perspective, Knowledge Retrievers have been built to extricate explicit data documents from a large corpus of databases with greater efficiency and accuracy. Recent research has also focused on superior inference by providing efficient attention to longer input sequences. In this paper, we summarize and examine the current state-of-the-art (SOTA) NLP models that have been employed for numerous NLP tasks for optimal performance and efficiency. We provide a detailed understanding and functioning of the different architectures, a taxonomy of NLP designs, comparative evaluations, and future directions in NLP.
翻译:近年来,自然语言处理(NLP)模式在文字分类、机器翻译、认知对话系统、通过自然语言理解(NLU)信息检索和自然语言生成(NLG)等语言和语义任务方面取得了惊人的成功,这主要归功于开创性变异器结构,导致诸如BERT、GPT(I、II、III)等设计。虽然这些大型模型取得了前所未有的绩效,但它们的计算成本却很高。因此,最近的国家语言处理(NLP)结构中的一些结构利用了转让学习、修剪、量化和知识蒸馏的概念,实现了中度模型规模,同时保持了与其前身几乎相似的业绩。此外,为了减轻语言模型从知识提取角度提出的数据规模挑战,建立了知识检索器,以便以更高的效率和准确性从大型数据库中提取清晰的数据文件。最近的研究还侧重于通过高效关注更长时间的投入序列来提高判断力。在本文中,我们总结和审查当前的NP(SO)状态模式,并研究了目前对NP-L(SO)系统运作中的最佳做法结构进行一项不同的业绩评估。