
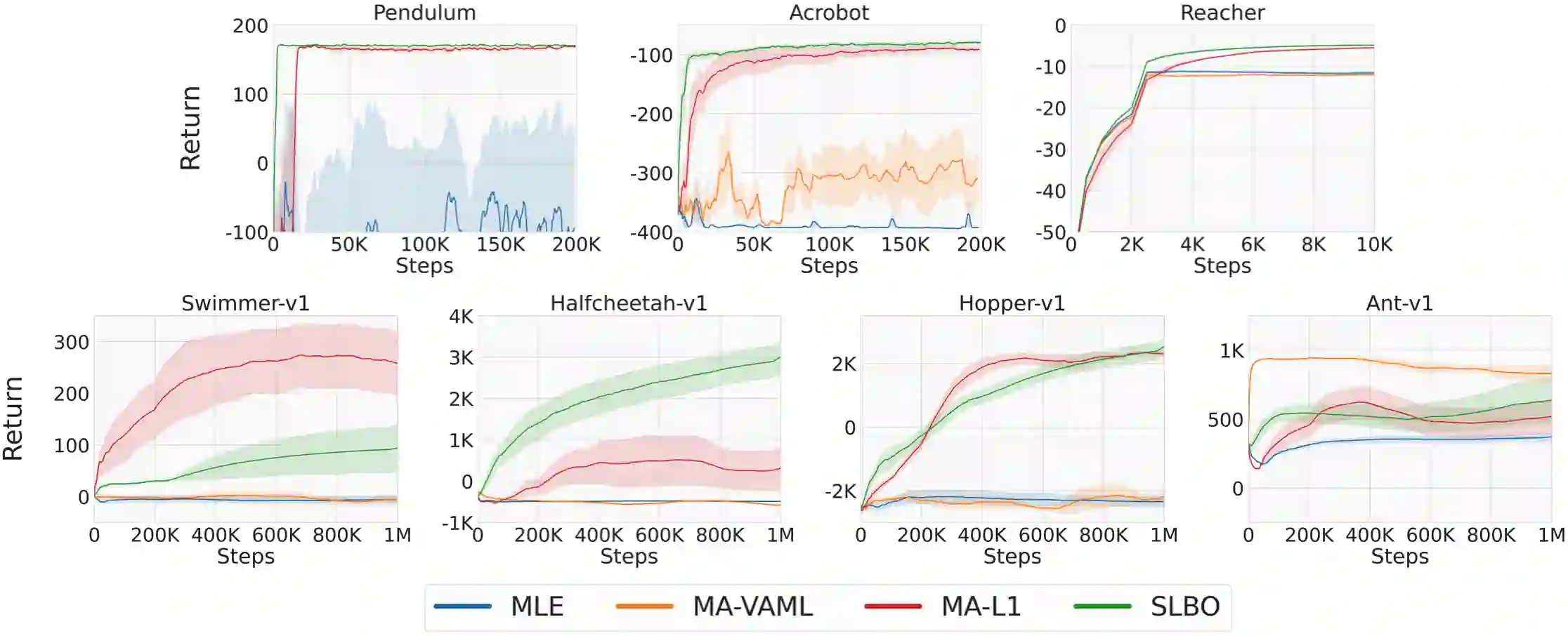
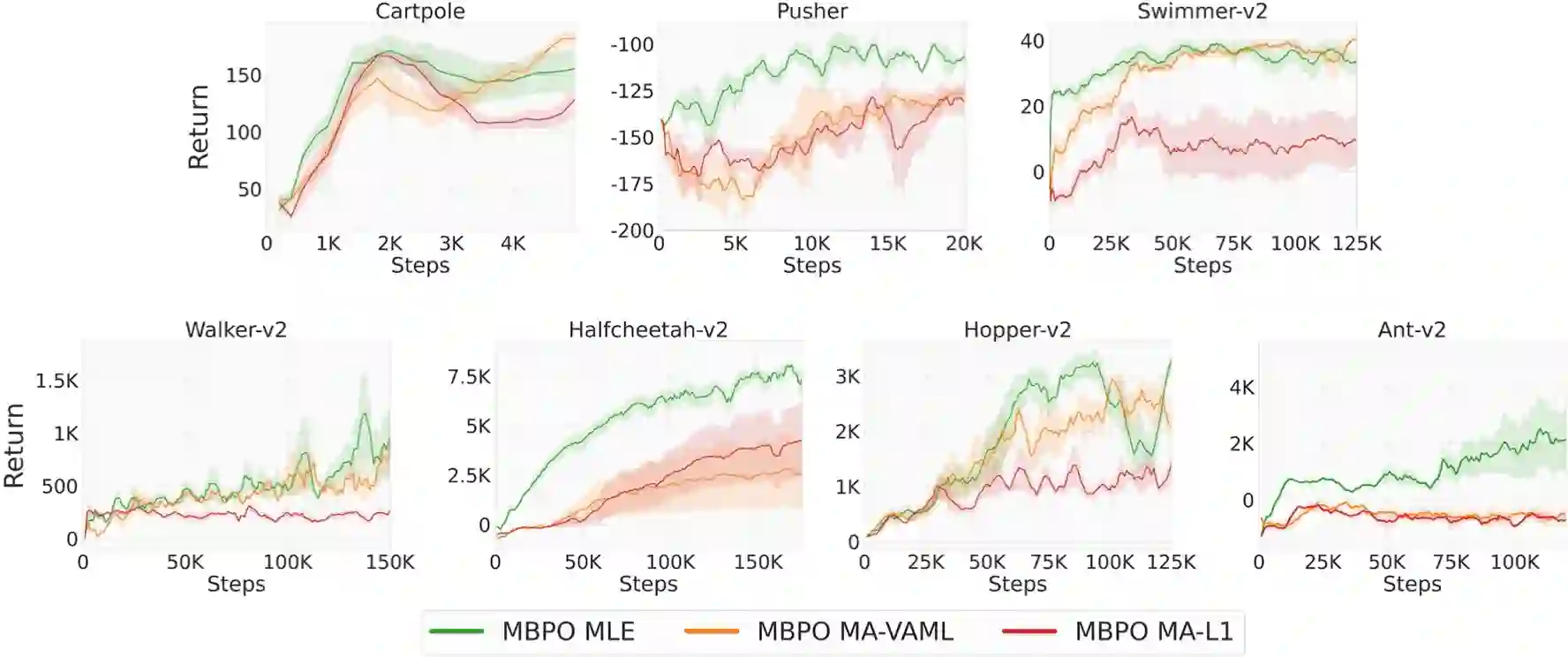
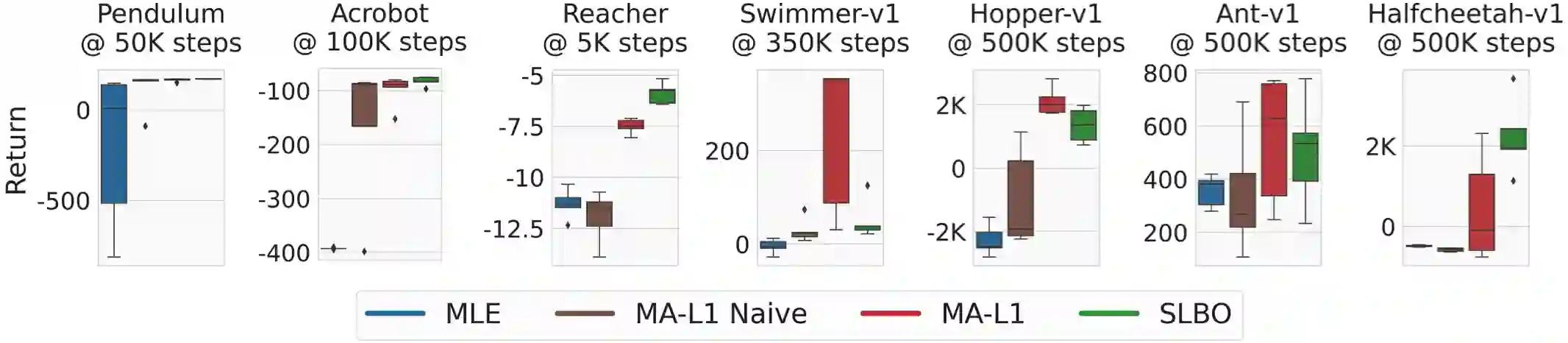
This work shows that value-aware model learning, known for its numerous theoretical benefits, is also practically viable for solving challenging continuous control tasks in prevalent model-based reinforcement learning algorithms. First, we derive a novel value-aware model learning objective by bounding the model-advantage i.e. model performance difference, between two MDPs or models given a fixed policy, achieving superior performance to prior value-aware objectives in most continuous control environments. Second, we identify the issue of stale value estimates in naively substituting value-aware objectives in place of maximum-likelihood in dyna-style model-based RL algorithms. Our proposed remedy to this issue bridges the long-standing gap in theory and practice of value-aware model learning by enabling successful deployment of all value-aware objectives in solving several continuous control robotic manipulation and locomotion tasks. Our results are obtained with minimal modifications to two popular and open-source model-based RL algorithms -- SLBO and MBPO, without tuning any existing hyper-parameters, while also demonstrating better performance of value-aware objectives than these baseline in some environments.
翻译:这项工作表明,以其众多理论利益著称的增值模型学习,在解决流行的基于模型的强化学习算法中具有挑战性的连续控制任务方面,实际上也是可行的。 首先,我们通过将两个模型优势(即模型性能差异)结合到两个模型优势(即模型性能差异)或具有固定政策的模型之间,在最连续的控制环境中实现优于先前的价值认知目标的优异性能,从而在两个模型(SLBO和MBPO)的流行和开放源码RL算法上,在天真地取代价值认知目标,以取代以新式模型为基础的RLL算法中的最大相似性能,从而得出我们的成果,同时在一些环境中,我们提出的解决这一问题的补救办法缩小了在价值认知模型学习理论和实践方面长期存在的差距,使所有价值认知目标能够成功地用于解决若干持续控制的机器人操纵和移动任务。我们的成果是通过对两种基于开放源码的通用RL算法(SLBO和MBO)进行最小的修改而获得的。

相关内容

Source: Apple - iOS 8

