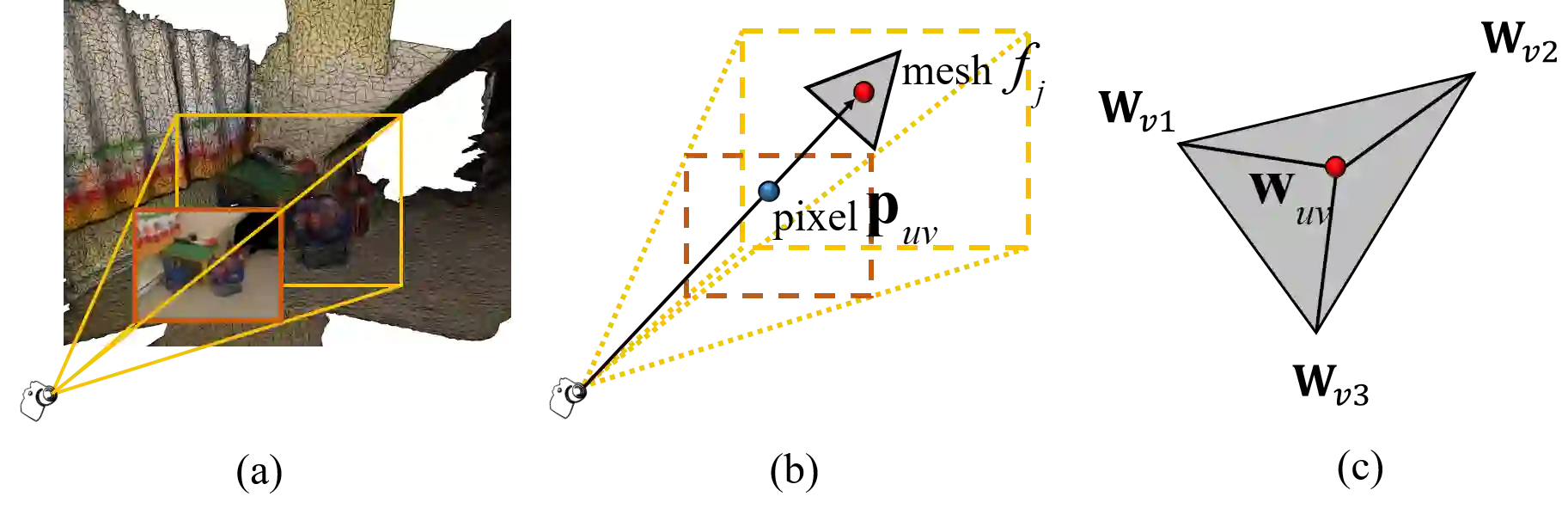
3D point cloud segmentation remains challenging for structureless and textureless regions. We present a new unified point-based framework for 3D point cloud segmentation that effectively optimizes pixel-level features, geometrical structures and global context priors of an entire scene. By back-projecting 2D image features into 3D coordinates, our network learns 2D textural appearance and 3D structural features in a unified framework. In addition, we investigate a global context prior to obtain a better prediction. We evaluate our framework on ScanNet online benchmark and show that our method outperforms several state-of-the-art approaches. We explore synthesizing camera poses in 3D reconstructed scenes for achieving higher performance. In-depth analysis on feature combinations and synthetic camera pose verify that features from different modalities benefit each other and dense camera pose sampling further improves the segmentation results.
翻译:3D点云分解仍对无结构和无纹理区域具有挑战性。 我们为 3D点云分解提供了一个新的统一点基框架, 有效地优化像素级特征、 几何结构以及整个场景的全球背景背景。 通过将 2D 图像特征回射为 3D 坐标, 我们的网络在一个统一的框架中学习了 2D 纹理外观和 3D 结构特征。 此外, 我们先调查一个全球背景, 然后再进行更好的预测。 我们评估了 ScanNet 在线基准框架, 并显示我们的方法优于若干最先进的方法。 我们探索了三D 重建场的相机合成, 以达到更高的性能。 对地貌组合和合成相机的深入分析显示, 不同模式的特征能够相互受益, 而密度的相机则能进一步改进分解结果 。