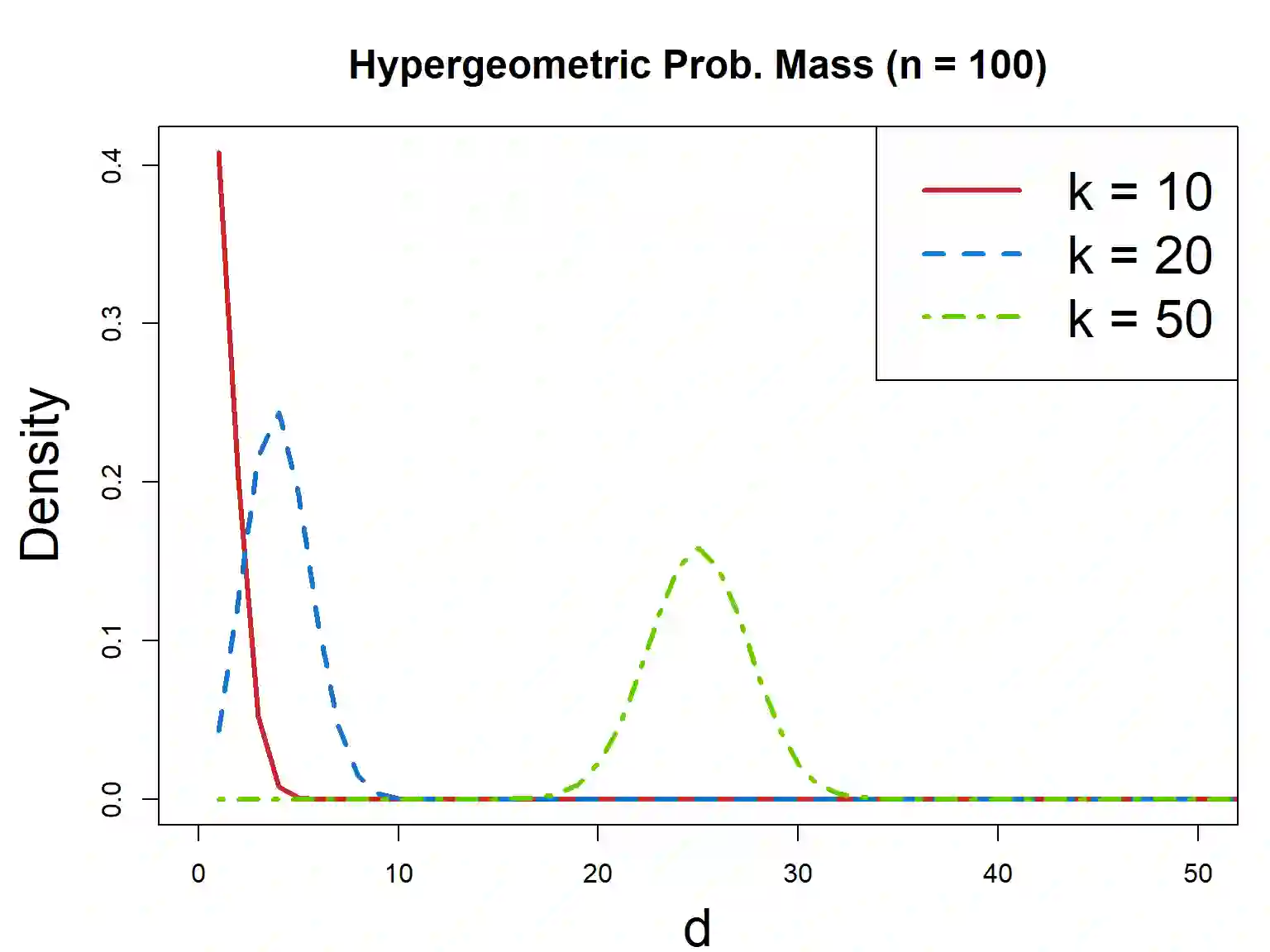
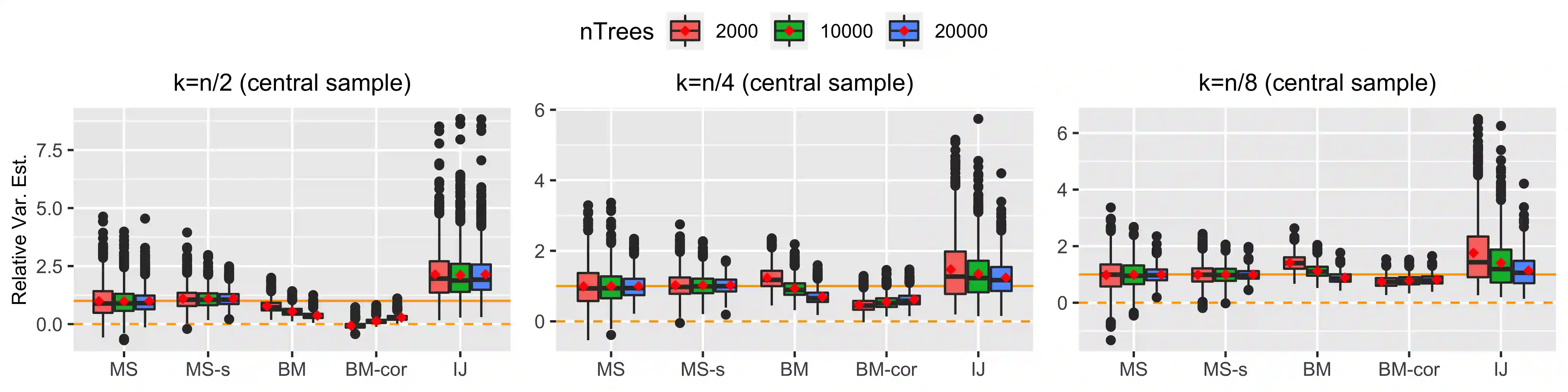
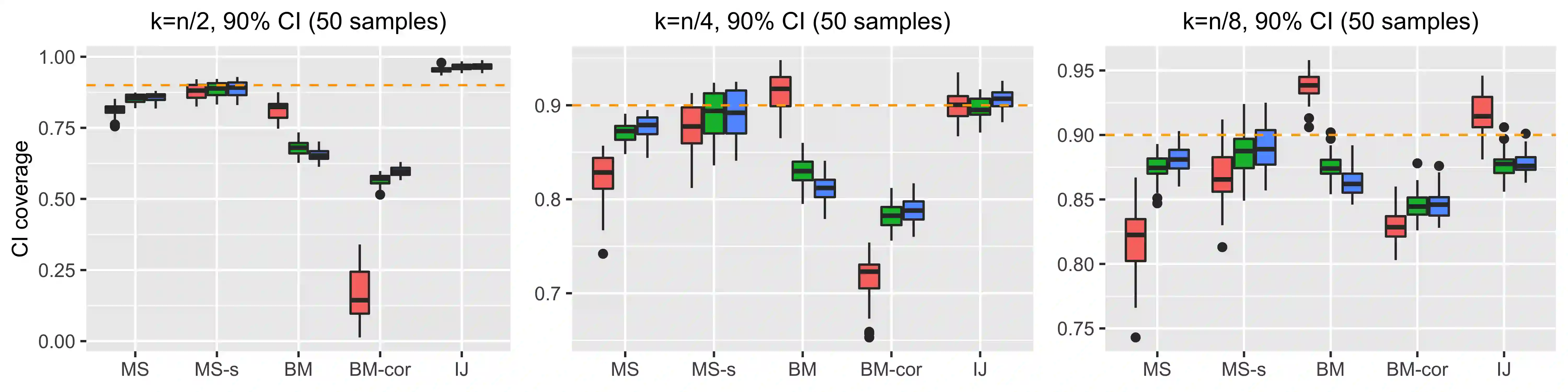
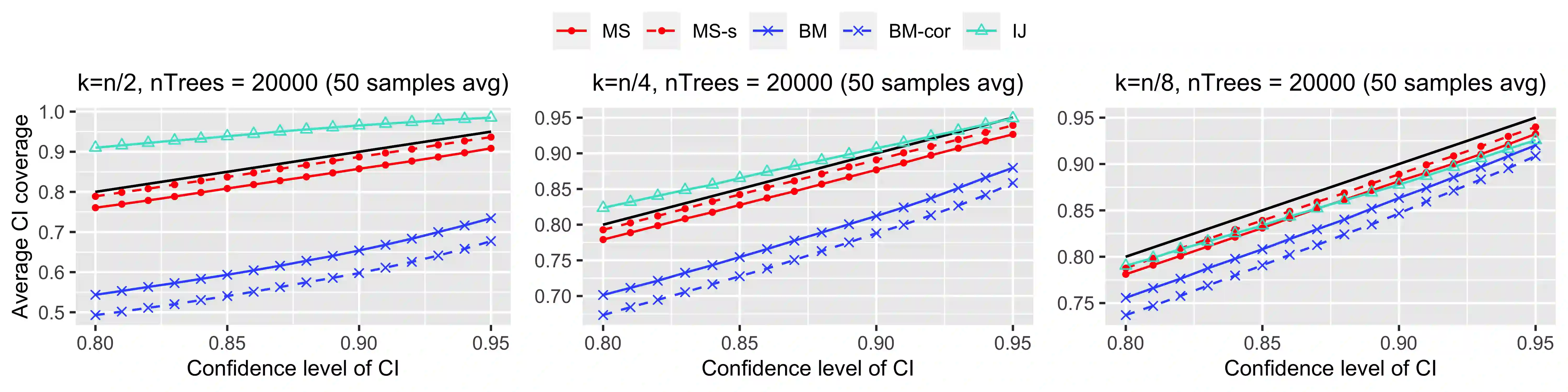
Ensemble methods based on subsampling, such as random forests, are popular in applications due to their high predictive accuracy. Existing literature views a random forest prediction as an infinite-order incomplete U-statistic to quantify its uncertainty. However, these methods focus on a small subsampling size of each tree, which is theoretically valid but practically limited. This paper develops an unbiased variance estimator based on incomplete U-statistics, which allows the tree size to be comparable with the overall sample size, making statistical inference possible in a broader range of real applications. Simulation results demonstrate that our estimators enjoy lower bias and more accurate confidence interval coverage without additional computational costs. We also propose a local smoothing procedure to reduce the variation of our estimator, which shows improved numerical performance when the number of trees is relatively small. Further, we investigate the ratio consistency of our proposed variance estimator under specific scenarios. In particular, we develop a new "double U-statistic" formulation to analyze the Hoeffding decomposition of the estimator's variance.
翻译:随机森林等基于子抽样的方法,由于预测准确度高,在应用中很受欢迎。现有文献认为随机森林预测是一种无限的、不完全的U-统计性来量化其不确定性。然而,这些方法侧重于每一棵树的小型子抽样,在理论上是有效的,但实际上是有限的。本文根据不完整的U-统计性方法,开发了一个公正的差异估计器,使树木大小能够与总体抽样规模相比,从而有可能在更广泛的实际应用中进行统计推断。模拟结果表明,我们的测算器享有较低的偏差,在不增加计算费用的情况下,具有更准确的置信间隔。我们还提议了一个本地的平滑动程序,以降低我们的测算器的变异性,这表明在树木数量相对较少的情况下,其数值性能有所改善。此外,我们调查了在特定情况下我们提议的差异估计器的比重是否一致。我们特别开发了一种新的“双重U-统计性”配方,以分析测算器差异的何等分差。