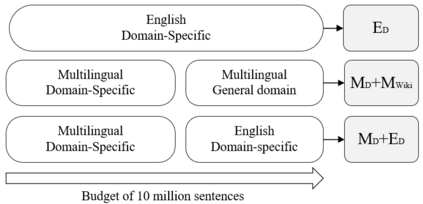
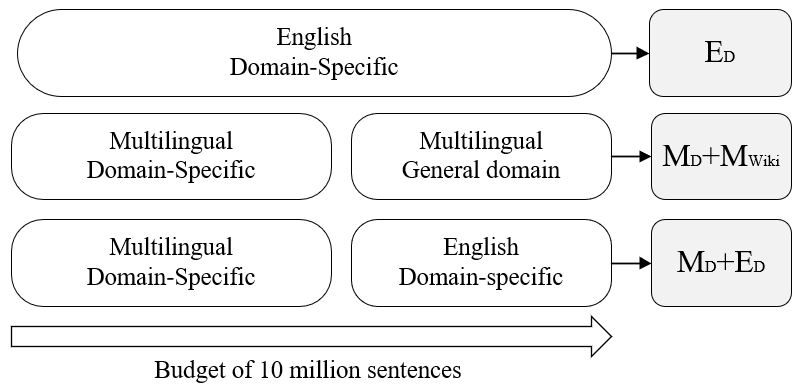
Domain adaptive pretraining, i.e. the continued unsupervised pretraining of a language model on domain-specific text, improves the modelling of text for downstream tasks within the domain. Numerous real-world applications are based on domain-specific text, e.g. working with financial or biomedical documents, and these applications often need to support multiple languages. However, large-scale domain-specific multilingual pretraining data for such scenarios can be difficult to obtain, due to regulations, legislation, or simply a lack of language- and domain-specific text. One solution is to train a single multilingual model, taking advantage of the data available in as many languages as possible. In this work, we explore the benefits of domain adaptive pretraining with a focus on adapting to multiple languages within a specific domain. We propose different techniques to compose pretraining corpora that enable a language model to both become domain-specific and multilingual. Evaluation on nine domain-specific datasets-for biomedical named entity recognition and financial sentence classification-covering seven different languages show that a single multilingual domain-specific model can outperform the general multilingual model, and performs close to its monolingual counterpart. This finding holds across two different pretraining methods, adapter-based pretraining and full model pretraining.
翻译:适应性预备培训,即继续不受监督地对特定领域文本的语言模式进行预先培训,改进了本领域下游任务文本的建模。许多现实世界应用都以特定领域文本为基础,例如与财务或生物医学文件合作,这些应用往往需要支持多种语言。然而,由于规章、立法或仅仅缺乏特定语言和特定领域文本,这类情景的大规模特定领域多语种培训预培训数据可能难以获得。一个解决办法是培训单一多语言模式,利用尽可能多的语言提供的数据。在这项工作中,我们探索以特定领域适应多种语言为重点的领域适应性预培训的好处。我们提出不同技术来构建预先培训团,使语言模式既成为特定领域又多语言。对九个特定领域数据集的评价――生物医学名称实体识别和财务判决分类覆盖7种不同语言。一个单一的多语言特定领域模式可以超越一般多语言模式,并运行接近单一语言培训前的模型。这一发现在两种不同的培训前方法之间,在培训前采用不同的培训前方法。