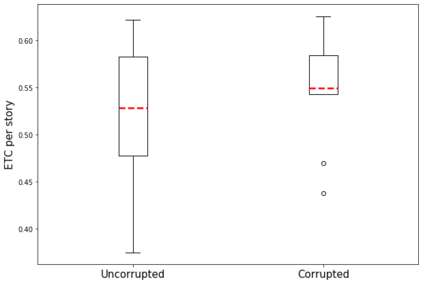
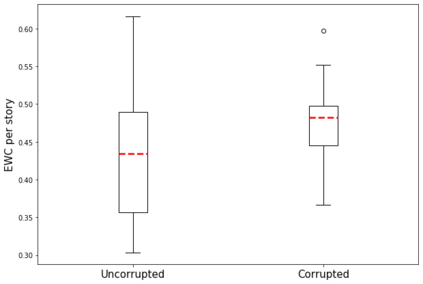
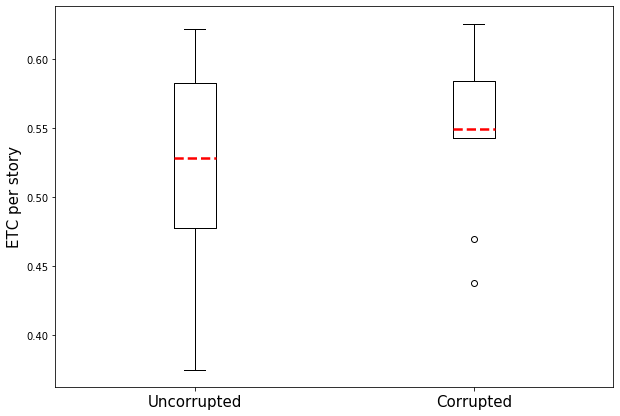
Automated story generation remains a difficult area of research because it lacks strong objective measures. Generated stories may be linguistically sound, but in many cases suffer poor narrative coherence required for a compelling, logically-sound story. To address this, we present Fabula Entropy Indexing (FEI), an evaluation method to assess story coherence by measuring the degree to which human participants agree with each other when answering true/false questions about stories. We devise two theoretically grounded measures of reader question-answering entropy, the entropy of world coherence (EWC), and the entropy of transitional coherence (ETC), focusing on global and local coherence, respectively. We evaluate these metrics by testing them on human-written stories and comparing against the same stories that have been corrupted to introduce incoherencies. We show that in these controlled studies, our entropy indices provide a reliable objective measure of story coherence.
翻译:自动化故事生成仍是一个困难的研究领域,因为它缺乏强有力的客观措施。 生成的故事在语言上可能很健全,但在许多情况下,对于具有说服力的、逻辑上健全的故事来说,其描述性缺乏一致性。 为了解决这个问题,我们介绍了Fabula Entropy Inviceing(FeI),这是一个评估故事一致性的评估方法,通过测量人类参与者在回答真实/虚假的故事问题时彼此一致的程度来评估故事的一致性。我们设计了两种基于理论的读者问答的解答昆虫(即世界一致性(EWC)的导体(EWC))和过渡一致性(ETC)的昆虫(ETC),分别侧重于全球和地方的一致性(ETC),我们用人类写的故事来测试这些计量尺度,并比较被腐败的、导致不相容的相同故事。我们指出,在这些受控制的研究中,我们的诱变指数提供了可靠的、客观的故事一致性衡量尺度。