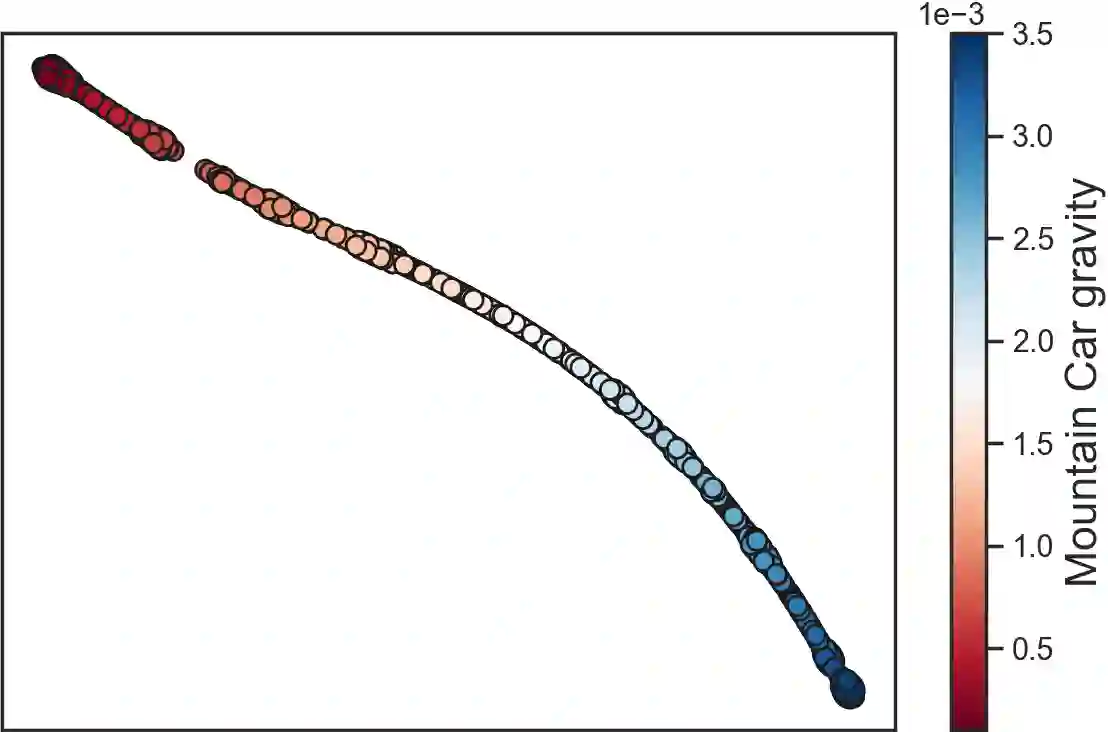
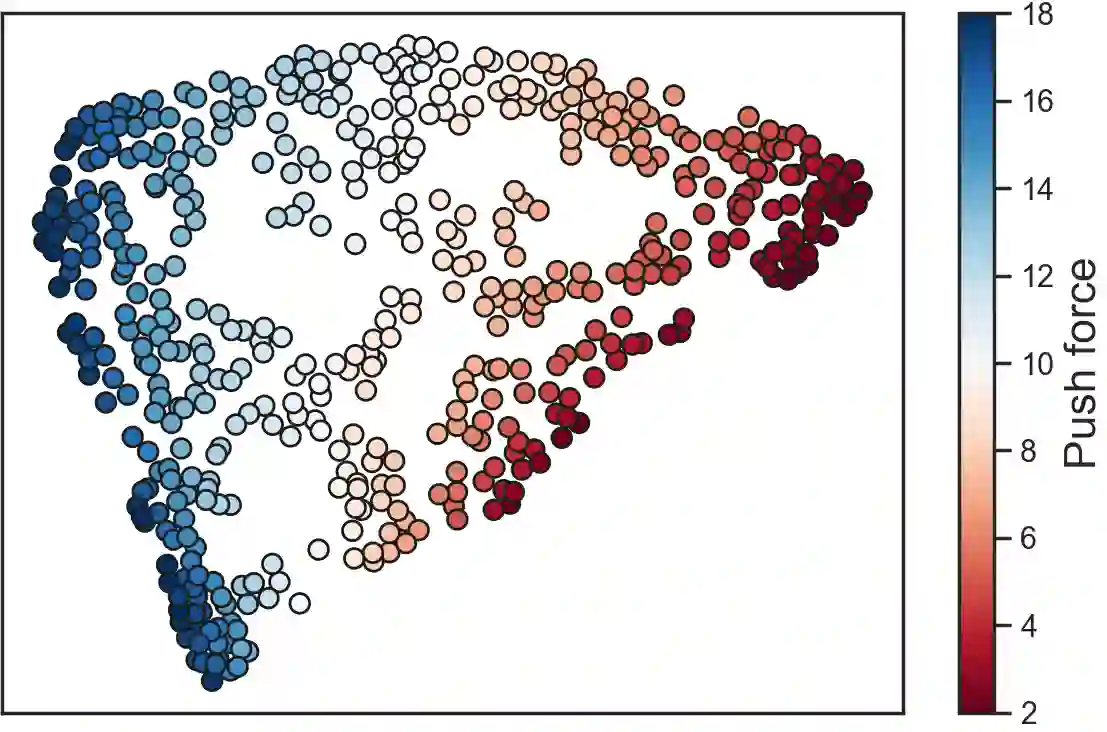
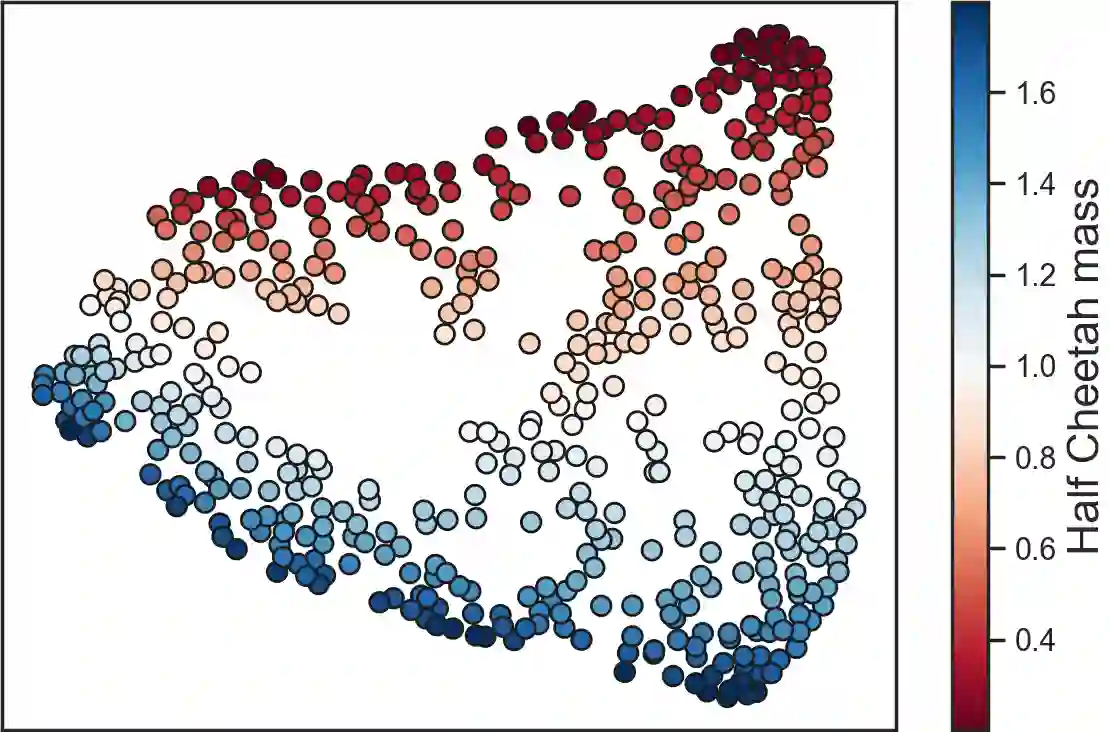
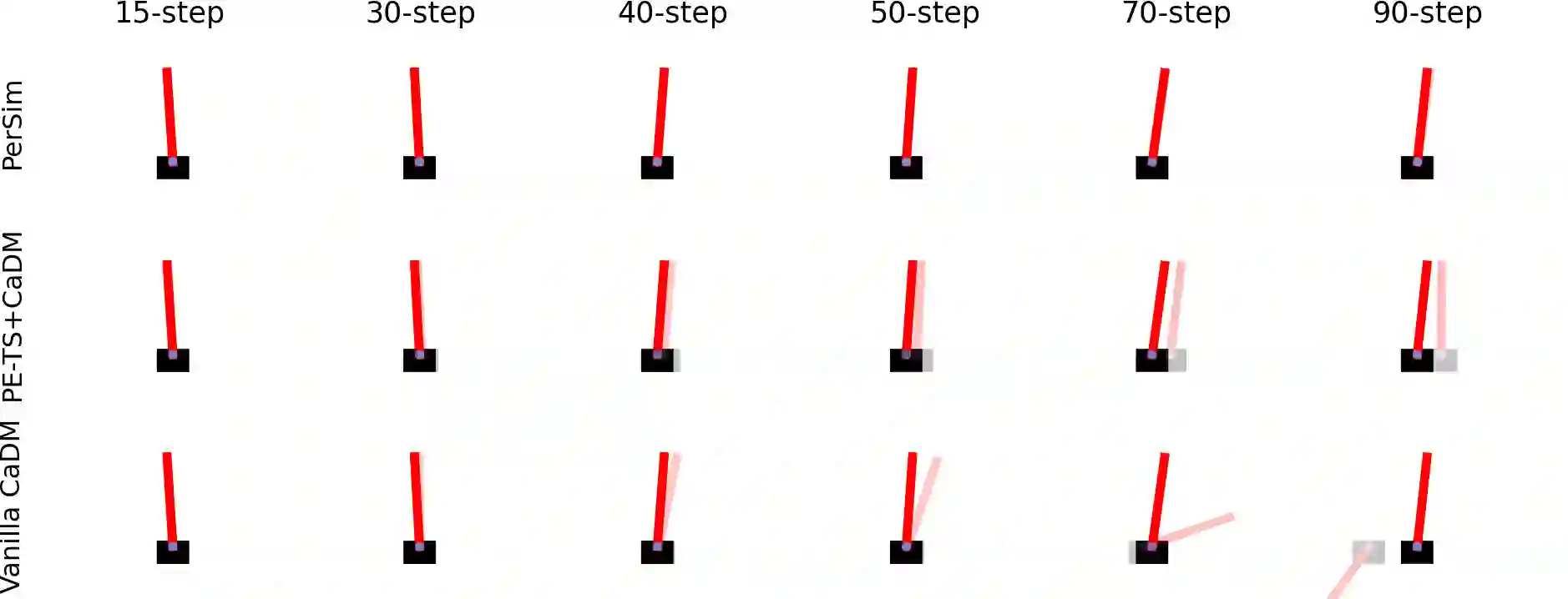
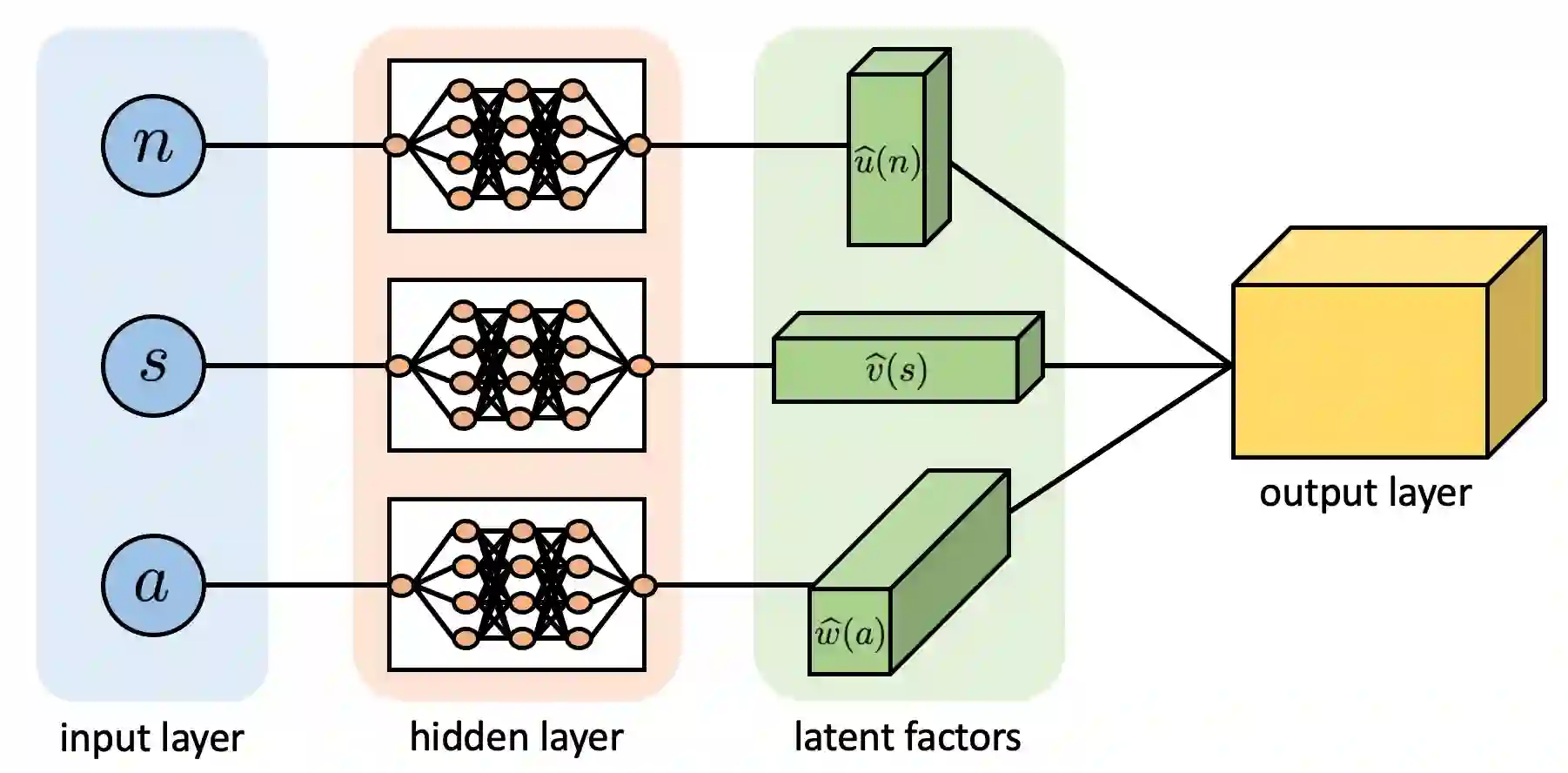
We consider offline reinforcement learning (RL) with heterogeneous agents under severe data scarcity, i.e., we only observe a single historical trajectory for every agent under an unknown, potentially sub-optimal policy. We find that the performance of state-of-the-art offline and model-based RL methods degrade significantly given such limited data availability, even for commonly perceived "solved" benchmark settings such as "MountainCar" and "CartPole". To address this challenge, we propose a model-based offline RL approach, called PerSim, where we first learn a personalized simulator for each agent by collectively using the historical trajectories across all agents prior to learning a policy. We do so by positing that the transition dynamics across agents can be represented as a latent function of latent factors associated with agents, states, and actions; subsequently, we theoretically establish that this function is well-approximated by a "low-rank" decomposition of separable agent, state, and action latent functions. This representation suggests a simple, regularized neural network architecture to effectively learn the transition dynamics per agent, even with scarce, offline data.We perform extensive experiments across several benchmark environments and RL methods. The consistent improvement of our approach, measured in terms of state dynamics prediction and eventual reward, confirms the efficacy of our framework in leveraging limited historical data to simultaneously learn personalized policies across agents.
翻译:我们考虑在数据严重匮乏的情况下,与各种物剂进行离线强化学习(RL),在数据严重匮乏的情况下,我们只观察到每个物剂在未知的、潜在的亚最佳政策下的一个单一历史轨迹。我们发现,由于数据供应有限,即使对于通常认为的“溶解”基准设置,如“Mountaincar”和“CartPole”,最先进的脱线方法,我们考虑的是,我们只看到在一种未知的、潜在的亚于最佳的政策下,我们只看到每个物剂都有一个单一的历史轨迹。我们发现,鉴于这种最先进的离线和基于模型的强化学习(RL)方法的绩效,我们发现,由于数据供应有限,跨线的过渡动态可以同时代表与物剂、州和行动相关的潜在因素的潜在功能;随后,我们理论上确定,这一功能与“低级”脱钩的物剂、状态和行动潜伏功能相近相近。这一表述表明,在学习政策之前,要使用所有物剂之间的历史轨迹的轨迹。我们从一些简单的网络结构来有效地学习各种个人性动态的过渡性动态,在历史实验室中进行广泛的实验。