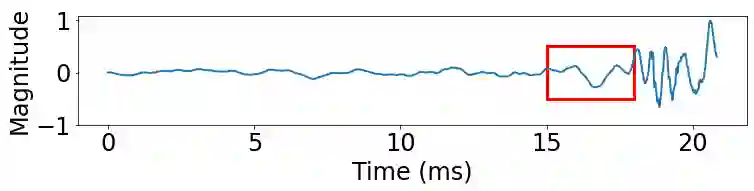
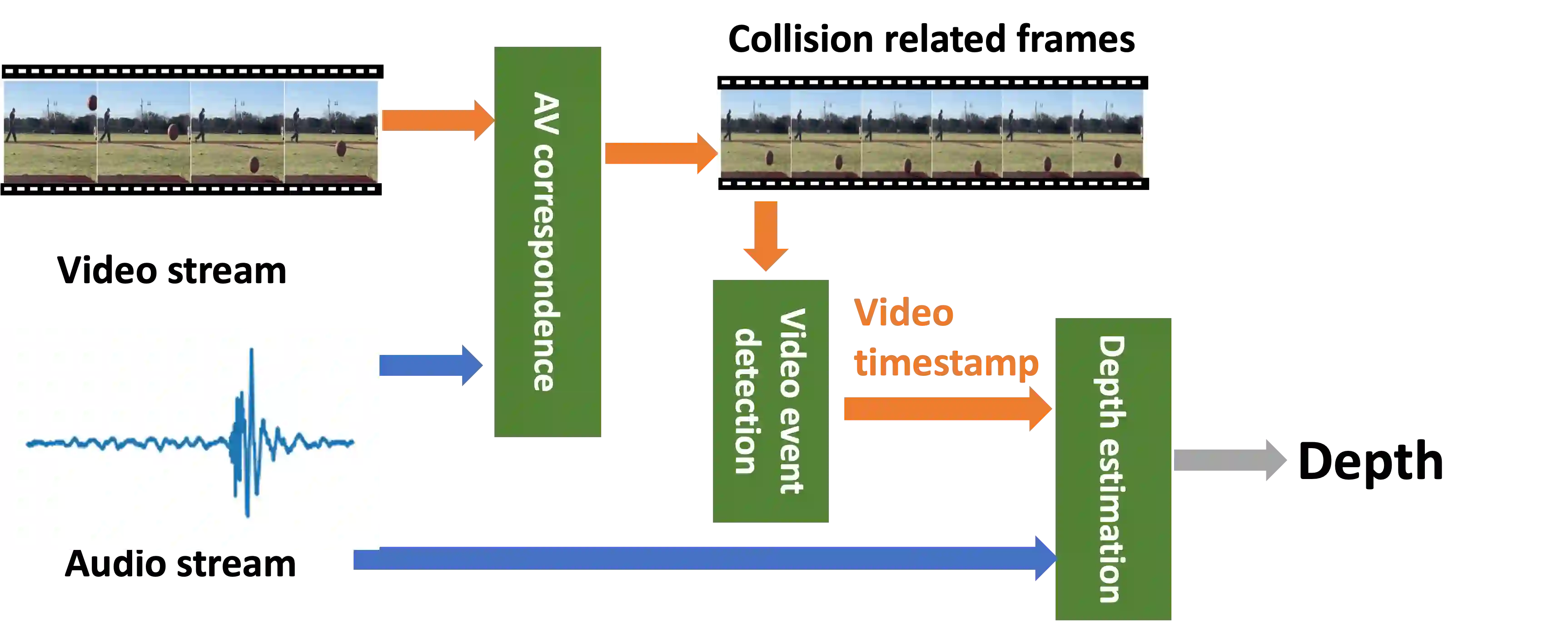
Depth estimation enables a wide variety of 3D applications, such as robotics, autonomous driving, and virtual reality. Despite significant work in this area, it remains open how to enable accurate, low-cost, high-resolution, and large-range depth estimation. Inspired by the flash-to-bang phenomenon (\ie hearing the thunder after seeing the lightning), this paper develops FBDepth, the first audio-visual depth estimation framework. It takes the difference between the time-of-flight (ToF) of the light and the sound to infer the sound source depth. FBDepth is the first to incorporate video and audio with both semantic features and spatial hints for range estimation. It first aligns correspondence between the video track and audio track to locate the target object and target sound in a coarse granularity. Based on the observation of moving objects' trajectories, FBDepth proposes to estimate the intersection of optical flow before and after the sound production to locate video events in time. FBDepth feeds the estimated timestamp of the video event and the audio clip for the final depth estimation. We use a mobile phone to collect 3000+ video clips with 20 different objects at up to $50m$. FBDepth decreases the Absolute Relative error (AbsRel) by 55\% compared to RGB-based methods.
翻译:深度估测可以实现多种3D应用, 如机器人、自主驾驶和虚拟现实。 尽管在这方面做了大量工作, 但它仍然可以允许准确、 低成本、 高分辨率和大范围的深度估测。 受闪光到闪光现象的启发( 在看到闪电后听到雷雷声), 本文开发了第一个视听深度估测框架FBDepeh。 它会考虑光线飞行时间( ToF) 和声音推导音源深度之间的差别。 FBDept是第一个将视频和音频包含语义特征和空间提示的视频和音频纳入范围估测的软件。 它首先将视频音轨和音频轨之间的对应对齐, 以粗微的颗粒定位目标对象和目标声音。 根据对移动物体轨迹的观察, FBDepteh 提议估算光流在声音制作前后的交错点, 以便及时定位视频事件。 FBBDepteh为视频事件的估计时间印本和最后深度估测距的音频剪。 我们用55A 将移动手机的频率到RB, 将50 至RB 。 我们用直径 将50 级的底的频率递解到RB 。