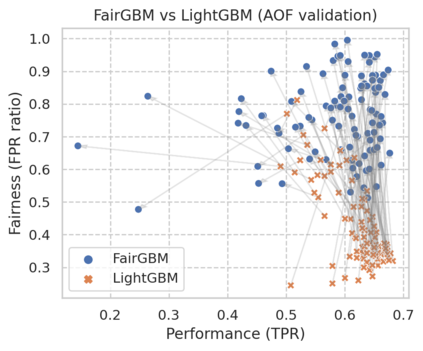
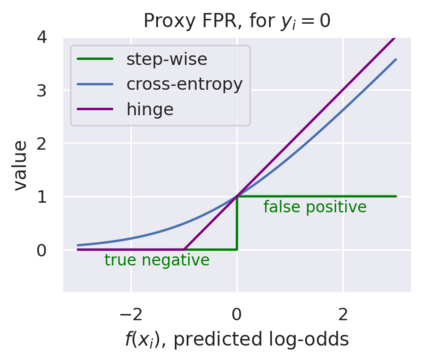
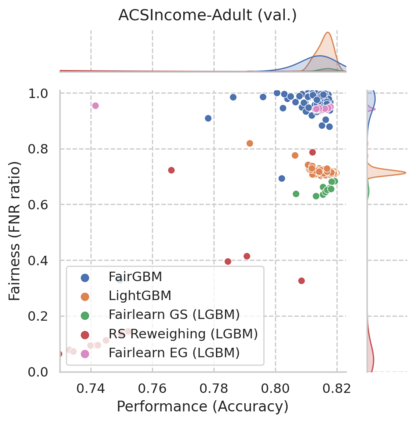
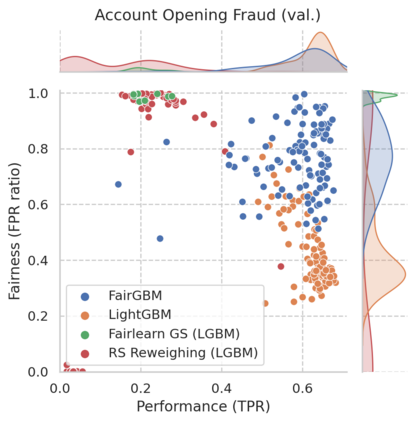
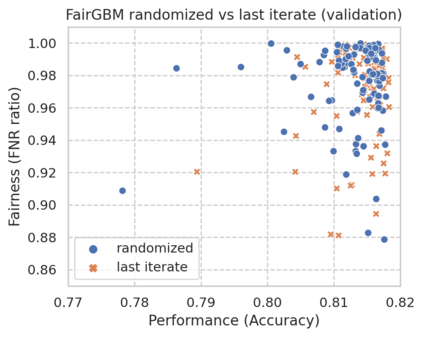
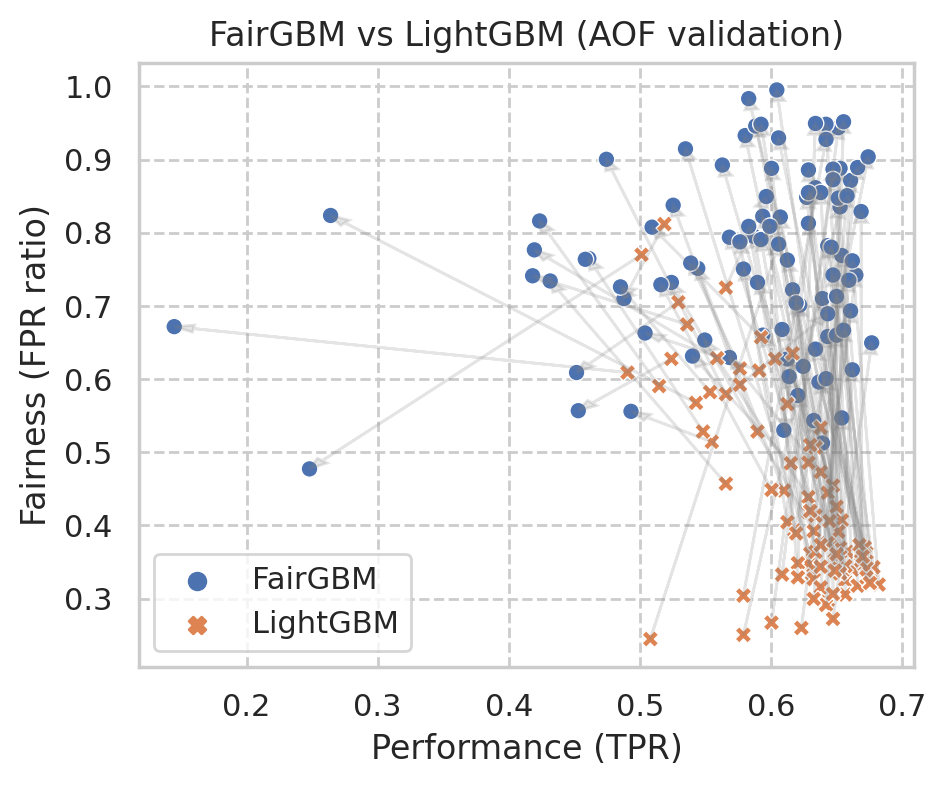
Machine Learning (ML) algorithms based on gradient boosted decision trees (GBDT) are still favored on many tabular data tasks across various mission critical applications, from healthcare to finance. However, GBDT algorithms are not free of the risk of bias and discriminatory decision-making. Despite GBDT's popularity and the rapid pace of research in fair ML, existing in-processing fair ML methods are either inapplicable to GBDT, incur in significant train time overhead, or are inadequate for problems with high class imbalance. We present FairGBM, a learning framework for training GBDT under fairness constraints with little to no impact on predictive performance when compared to unconstrained LightGBM. Since common fairness metrics are non-differentiable, we employ a ``proxy-Lagrangian'' formulation using smooth convex error rate proxies to enable gradient-based optimization. Additionally, our open-source implementation shows an order of magnitude speedup in training time when compared with related work, a pivotal aspect to foster the widespread adoption of FairGBM by real-world practitioners.
翻译:基于梯度提升决策树(GBDT)的机器学习(ML)算法仍然有利于从保健到金融等各种任务关键应用的许多表格数据任务,然而,GBT算法并非没有偏见和歧视性决策的风险。尽管GBT的受欢迎程度和公平ML研究的快速速度,但现有的在加工过程中的公平ML方法或不适用于GBDT, 产生大量的训练时间管理费,或不足以解决高等级不平衡的问题。我们提出了FairGBM,这是一个在公平限制下培训GBD的学习框架,与不受限制的LightGBM相比,对预测性能的影响很小,几乎没有任何影响。由于通用的公平指标是不可区别的,我们采用了“proxy-Lagrangian”的配方,使用平滑的conx误率准轴来进行梯度优化。此外,我们的公开源实施表明培训时间与相关工作相比,在培训时有一定的强度加速度,这是促进现实世界从业人员广泛采用公平GBM的关键方面。