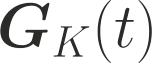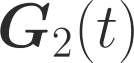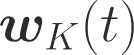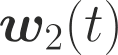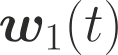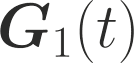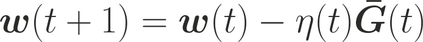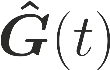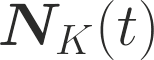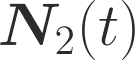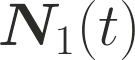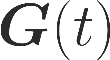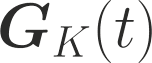One of the main focus in federated learning (FL) is the communication efficiency since a large number of participating edge devices send their updates to the edge server at each round of the model training. Existing works reconstruct each model update from edge devices and implicitly assume that the local model updates are independent over edge devices. In FL, however, the model update is an indirect multi-terminal source coding problem, also called as the CEO problem where each edge device cannot observe directly the gradient that is to be reconstructed at the decoder, but is rather provided only with a noisy version. The existing works do not leverage the redundancy in the information transmitted by different edges. This paper studies the rate region for the indirect multiterminal source coding problem in FL. The goal is to obtain the minimum achievable rate at a particular upper bound of gradient variance. We obtain the rate region for the quadratic vector Gaussian CEO problem under unbiased estimator and derive an explicit formula of the sum-rate-distortion function in the special case where gradient are identical over edge device and dimension. Finally, we analyse communication efficiency of convex Minibatched SGD and non-convex Minibatched SGD based on the sum-rate-distortion function, respectively.
翻译:联合学习(FL)的主要焦点之一是通信效率,因为大量参与的边缘设备在每轮示范培训中向边缘服务器发送了最新消息。现有的工程从边缘设备重建每个模型更新,并隐含地假设本地模型更新是独立的边缘设备。但在FL, 模型更新是一个间接的多端源编码问题, 也被称为CEO问题, 即每个边缘设备无法直接观测拟在解码器上重建的梯度, 而只能提供一个响亮的版本。 现有的工程无法利用不同边缘传送的信息中的冗余。 本文研究FL间接多端源编码问题的频度区域。 目标是在梯度差异的特定上限范围内获得最小可实现的速率。 我们从不偏向的估测器下获取四向矢量高的CEausia CEuto问题的比例区域, 并在梯度为边缘装置和尺寸相同的特殊情况下, 得出一个超度调和调函数的明确公式。 最后, 我们分析了基于 convex Minixblaction 的 SGDGD和不使用Sgevlads- scostad scolt scolt 的Sgevlapple) 。