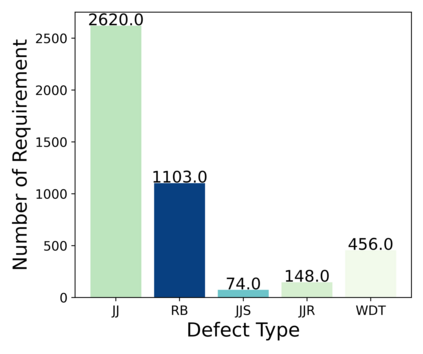
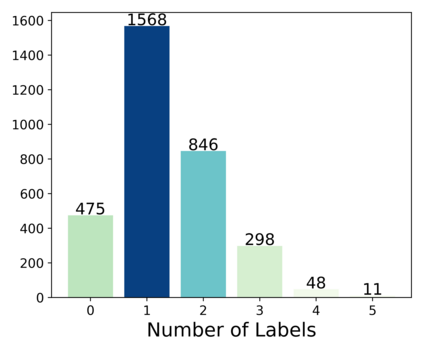
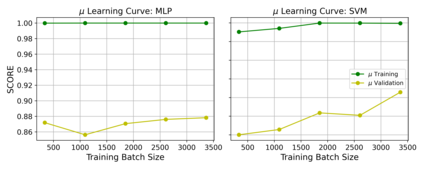
Requirements Engineering (RE) is the initial step towards building a software system. The success or failure of a software project is firmly tied to this phase, based on communication among stakeholders using natural language. The problem with natural language is that it can easily lead to different understandings if it is not expressed precisely by the stakeholders involved, which results in building a product different from the expected one. Previous work proposed to enhance the quality of the software requirements detecting language errors based on ISO 29148 requirements language criteria. The existing solutions apply classical Natural Language Processing (NLP) to detect them. NLP has some limitations, such as domain dependability which results in poor generalization capability. Therefore, this work aims to improve the previous work by creating a manually labeled dataset and using ensemble learning, Deep Learning (DL), and techniques such as word embeddings and transfer learning to overcome the generalization problem that is tied with classical NLP and improve precision and recall metrics using a manually labeled dataset. The current findings show that the dataset is unbalanced and which class examples should be added more. It is tempting to train algorithms even if the dataset is not considerably representative. Whence, the results show that models are overfitting; in Machine Learning this issue is solved by adding more instances to the dataset, improving label quality, removing noise, and reducing the learning algorithms complexity, which is planned for this research.
翻译:工程要求( RE) 是建立软件系统的第一步 。 软件项目的成败与这个阶段紧密相连, 其基础是使用自然语言的利益攸关方之间的沟通。 自然语言的问题在于, 如果所涉利益攸关方没有准确表达, 自然语言很容易导致不同的理解, 从而形成与预期不同的产品。 先前提出的提高软件要求质量的工作, 根据ISO 29148 要求语言标准, 检测语言错误; 现有解决方案应用古典自然语言处理( NLP) 来检测它们。 NLP 有一些局限性, 例如域的可依赖性, 导致一般化能力差。 因此, 这项工作的目的是通过创建人工标签数据集, 使用串联学习、 深学习( DL) 等技术来改进先前的工作。 先前提出的提高软件要求的质量, 以克服与古典NLP 相关的通用问题, 提高精确度, 并用手工标签数据集( NLP ) 来回顾标准。 目前的调查结果显示, 数据集是不平衡的, 应该增加哪些类示例。 因此, 这项工作的目的是通过创建算法来改进以前的算法,, 即使数据系统化的模型没有明显地消除了质量, 也能够消除数据。