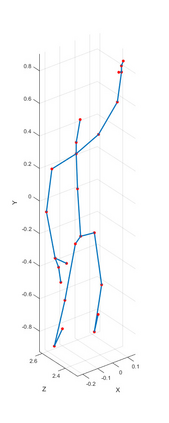
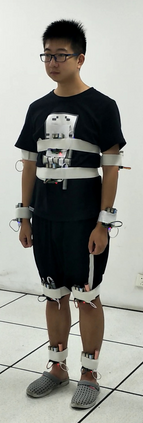
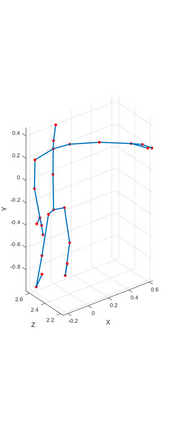
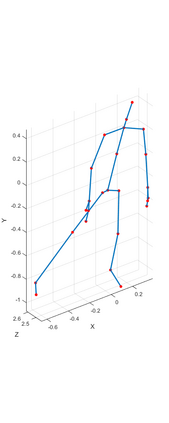
Human action recognition has been widely used in many fields of life, and many human action datasets have been published at the same time. However, most of the multi-modal databases have some shortcomings in the layout and number of sensors, which cannot fully represent the action features. Regarding the problems, this paper proposes a freely available dataset, named CZU-MHAD (Changzhou University: a comprehensive multi-modal human action dataset). It consists of 22 actions and three modals temporal synchronized data. These modals include depth videos and skeleton positions from a kinect v2 camera, and inertial signals from 10 wearable sensors. Compared with single modal sensors, multi-modal sensors can collect different modal data, so the use of multi-modal sensors can describe actions more accurately. Moreover, CZU-MHAD obtains the 3-axis acceleration and 3-axis angular velocity of 10 main motion joints by binding inertial sensors to them, and these data were captured at the same time. Experimental results are provided to show that this dataset can be used to study structural relationships between different parts of the human body when performing actions and fusion approaches that involve multi-modal sensor data.
翻译:在许多生活领域广泛使用了人类行动认知,同时还公布了许多人类行动数据集。然而,大多数多式数据库在传感器的布局和数量上有一些缺陷,无法充分代表行动特征。关于这些问题,本文件建议免费提供数据集,名为CZU-MAHAD(昌州大学:一个综合的多式人类行动数据集),由22个动作和3个模型同步时间数据组成。这些模型包括动脉V2相机的深度视频和骨架位置,以及10个可磨损传感器的惯性信号。与单一模式传感器相比,多式传感器可以收集不同的模式数据,因此多式传感器的使用可以更准确地描述行动。此外,CZU-MAHAD通过捆绑性惯性惯性传感器获得了3轴加速和3轴3轴角速度的10个主要运动连接,这些数据也同时被捕捉到。实验结果显示,该数据集可以用于研究多式传感器之间的结构关系,在进行多式移动时,采用多式传感器。