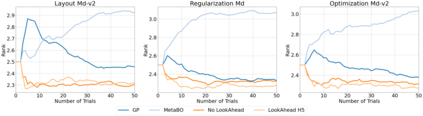
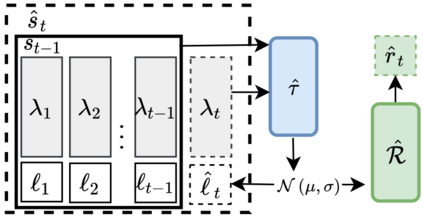
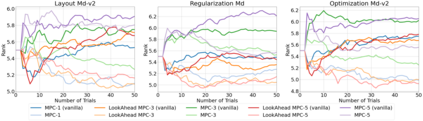
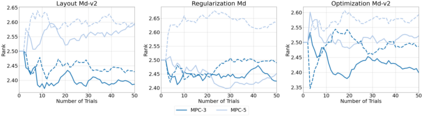
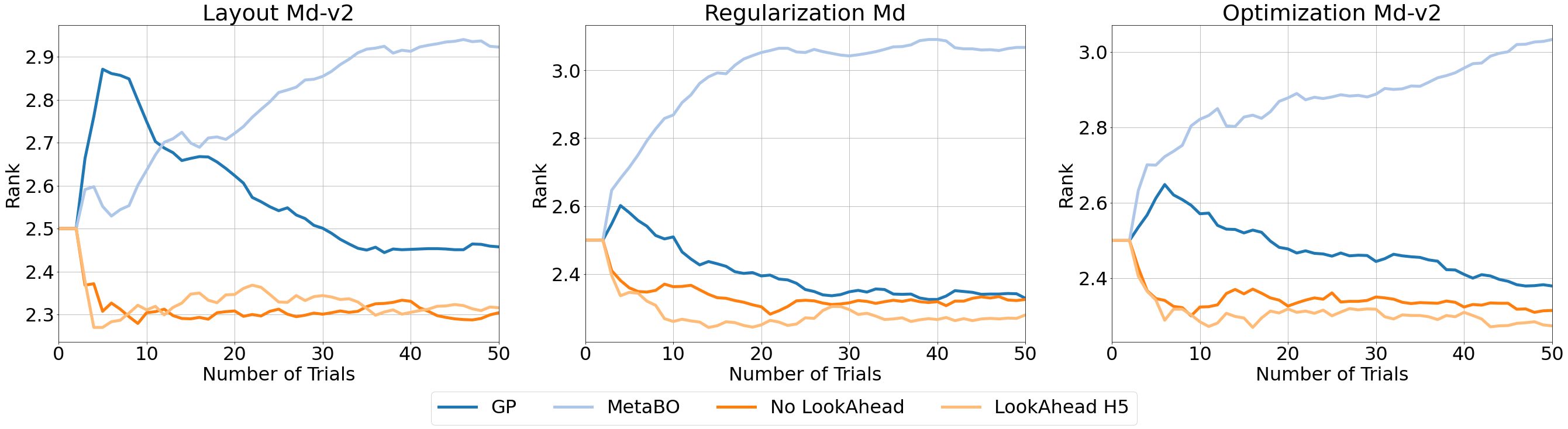
Hyperparameter optimization (HPO) is generally treated as a bi-level optimization problem that involves fitting a (probabilistic) surrogate model to a set of observed hyperparameter responses, e.g. validation loss, and consequently maximizing an acquisition function using a surrogate model to identify good hyperparameter candidates for evaluation. The choice of a surrogate and/or acquisition function can be further improved via knowledge transfer across related tasks. In this paper, we propose a novel transfer learning approach, defined within the context of model-based reinforcement learning, where we represent the surrogate as an ensemble of probabilistic models that allows trajectory sampling. We further propose a new variant of model predictive control which employs a simple look-ahead strategy as a policy that optimizes a sequence of actions, representing hyperparameter candidates to expedite HPO. Our experiments on three meta-datasets comparing to state-of-the-art HPO algorithms including a model-free reinforcement learning approach show that the proposed method can outperform all baselines by exploiting a simple planning-based policy.
翻译:超参数优化(HPO)一般被视为双级优化问题,它涉及将一个(概率)替代模型与一组观察到的超参数反应(例如验证损失)相匹配,从而最大限度地利用一种获取功能,使用一种替代模型确定良好的超参数候选人进行评估。通过跨相关任务的知识转让,替代和(或)获取功能的选择可以进一步改进。在本文件中,我们提议一种新型的转移学习方法,在基于模型的强化学习中加以界定,我们把替代模型作为允许轨迹取样的概率模型的组合。我们进一步提出一个新的模型预测控制变体,采用简单的外观战略作为优化一系列行动的政策,代表超参数候选人加速 HPO。我们在三个元数据集上进行的实验显示,与最新的HPO算法比较,包括一个无模型的强化学习方法,通过利用一个简单的基于规划的政策,可以超越所有基线。