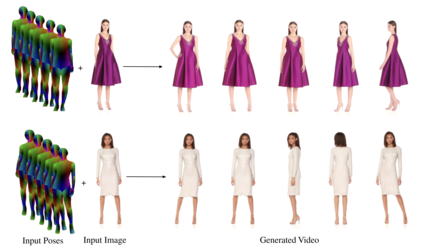
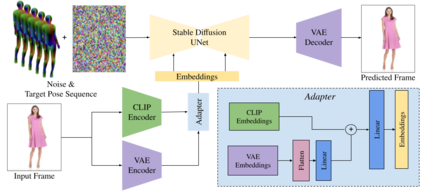
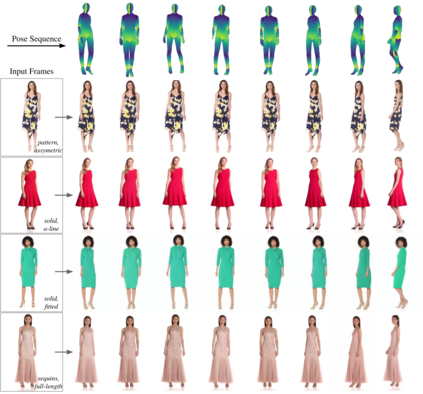
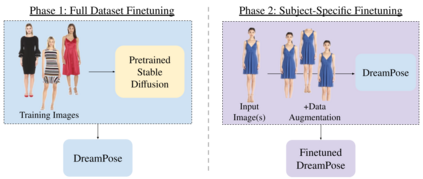
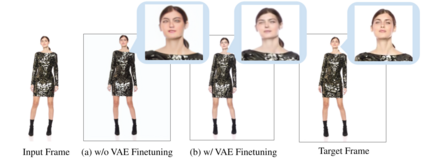
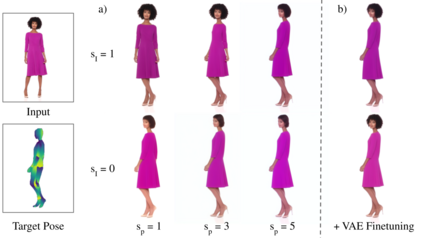
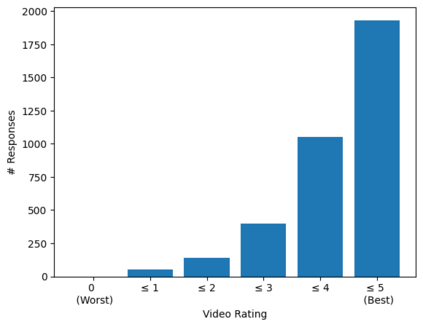
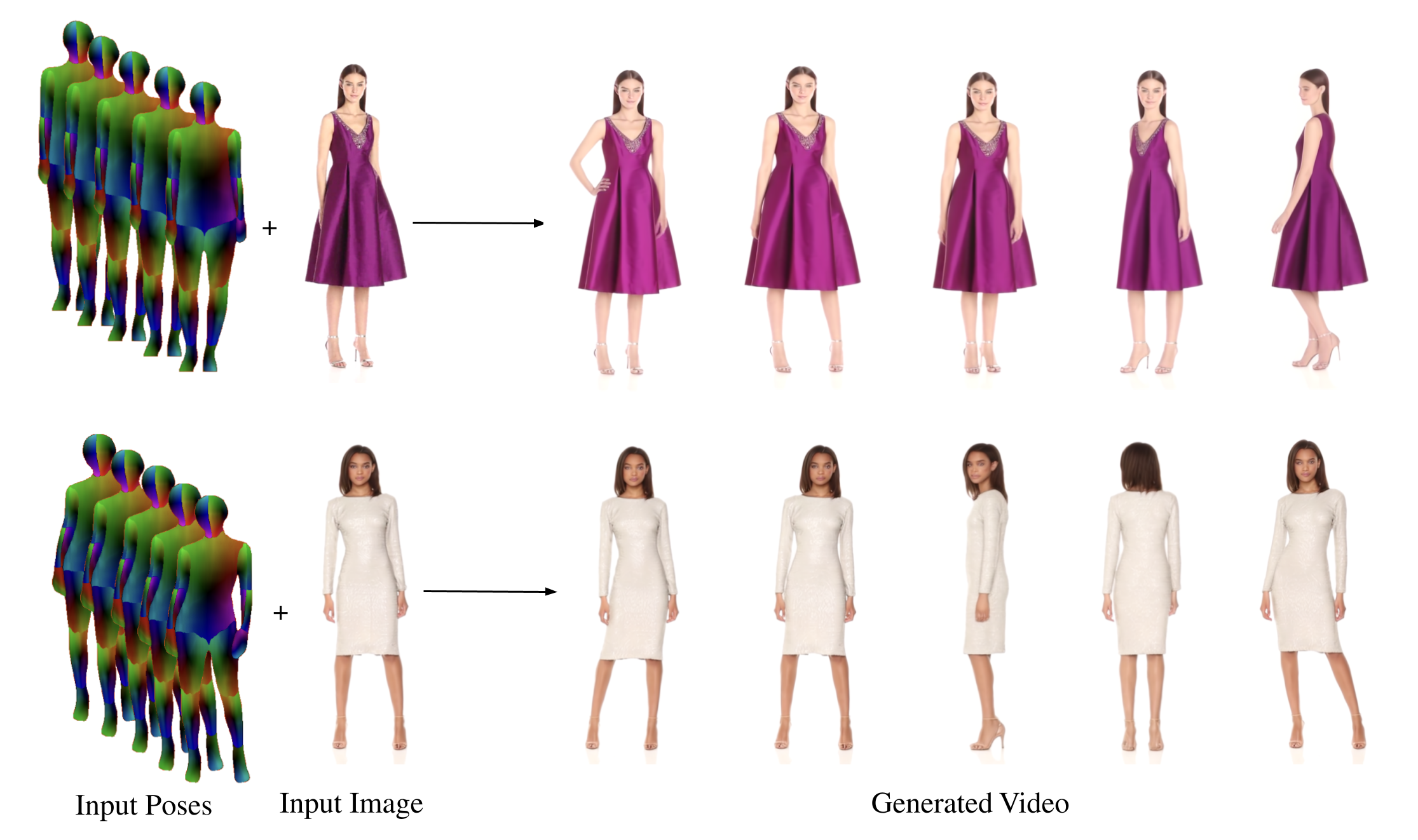
We present DreamPose, a diffusion-based method for generating animated fashion videos from still images. Given an image and a sequence of human body poses, our method synthesizes a video containing both human and fabric motion. To achieve this, we transform a pretrained text-to-image model (Stable Diffusion) into a pose-and-image guided video synthesis model, using a novel finetuning strategy, a set of architectural changes to support the added conditioning signals, and techniques to encourage temporal consistency. We fine-tune on a collection of fashion videos from the UBC Fashion dataset. We evaluate our method on a variety of clothing styles and poses, and demonstrate that our method produces state-of-the-art results on fashion video animation. Video results are available on our project page.
翻译:我们提出了 DreamPose,一种基于扩散的方法,用于从静态图像生成动态的时尚视频。给定一张图像和一系列人体姿势,我们的方法合成包含人体和布料动态的视频。为了实现这一点,我们将预训练的文本到图像模型(Stable Diffusion)转化为一种姿势和图像引导的视频合成模型,使用一种新颖的微调策略、一组架构变化来支持增加的条件信号,以及鼓励时间一致性的技术。我们在UBC Fashion数据集中的一组时尚视频上进行微调。我们评估了我们的方法在各种服装风格和姿势上的表现,并证明了我们的方法在时尚视频动画方面产生了最先进的结果。项目页面上提供了视频结果。