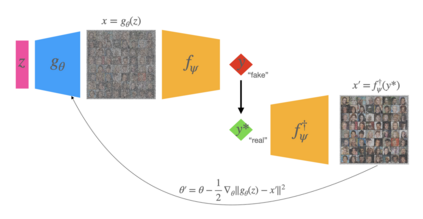
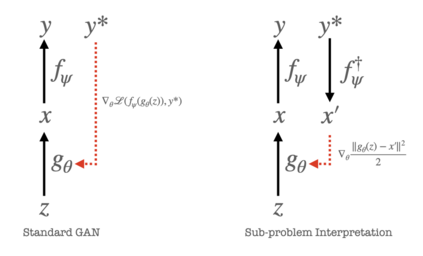
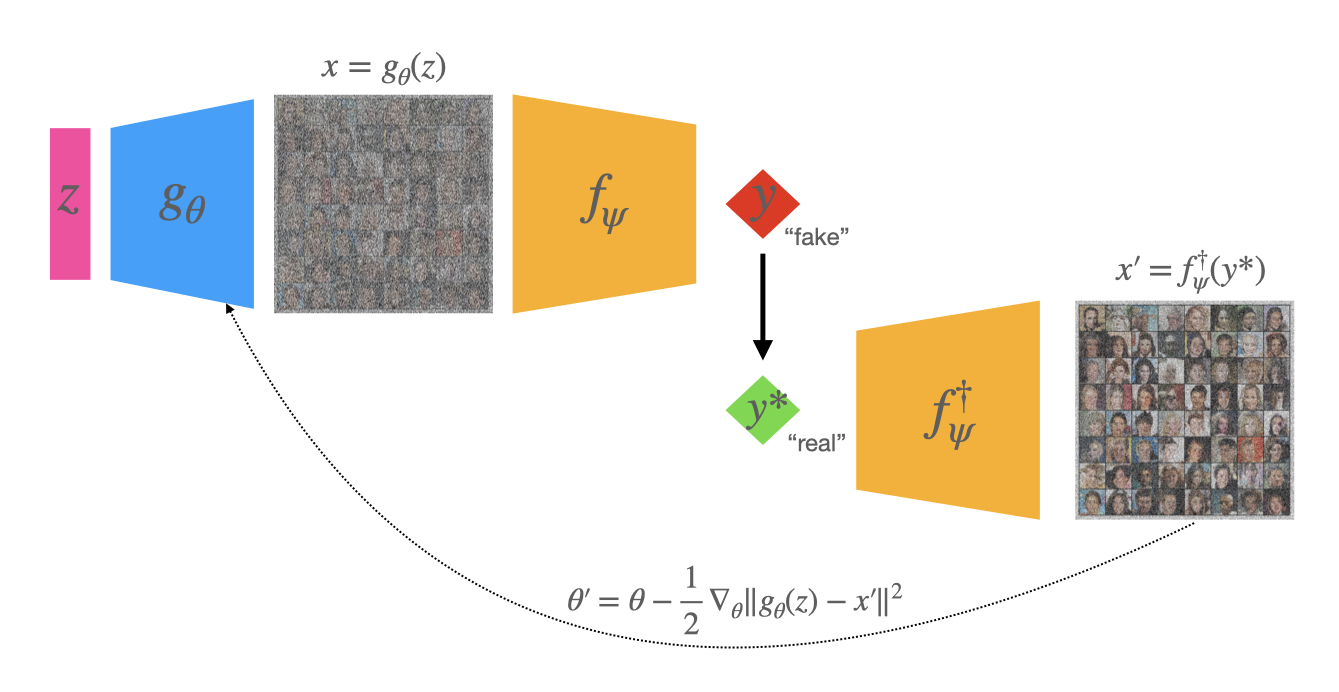
We present an alternative perspective on the training of generative adversarial networks (GANs), showing that the training step for a GAN generator decomposes into two implicit sub-problems. In the first, the discriminator provides new target data to the generator in the form of "inverse examples" produced by approximately inverting classifier labels. In the second, these examples are used as targets to update the generator via least-squares regression, regardless of the main loss specified to train the network. We experimentally validate our main theoretical result and discuss implications for alternative training methods that are made possible by making these sub-problems explicit. We also introduce a simple representation of inductive bias in networks, which we apply to describing the generator's output relative to its regression targets.
翻译:关于基因对抗网络(GANs)的培训,我们提出了另一种观点,表明GAN发电机的培训步骤分解成两个隐含的子问题。第一,歧视者以“反实例”的形式向发电机提供新的目标数据,其形式是大致倒转分类标签。第二,这些例子被用来作为目标,通过最小方位回归更新发电机,而不管培训网络的主要损失如何。我们实验地验证了我们的主要理论结果,并讨论了通过明确这些子问题而可能采用的替代培训方法的影响。我们还引入了简单的网络内隐含偏差的描述,用于描述发电机相对于其回归目标的产出。