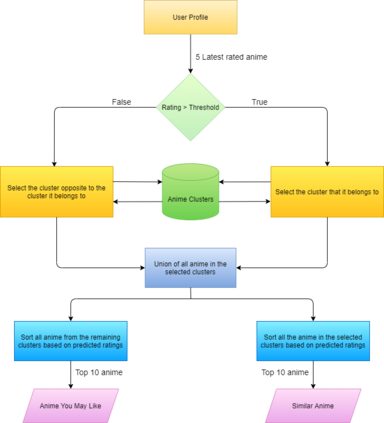
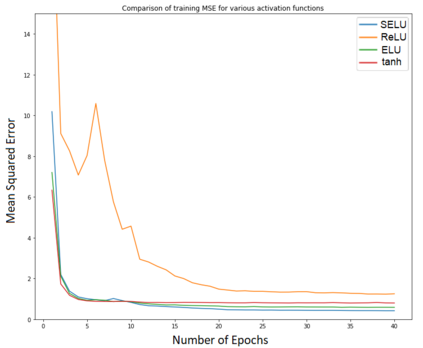
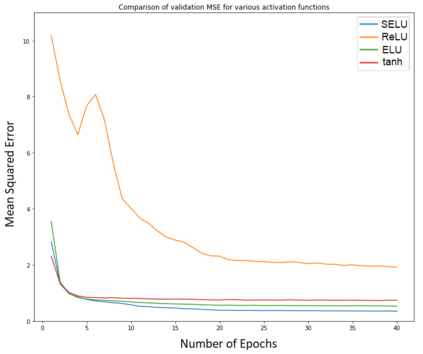
Anime is quite well-received today, especially among the younger generations. With many genres of available shows, more and more people are increasingly getting attracted to this niche section of the entertainment industry. As anime has recently garnered mainstream attention, we have insufficient information regarding users' penchant and watching habits. Therefore, it is an uphill task to build a recommendation engine for this relatively obscure entertainment medium. In this attempt, we have built a novel hybrid recommendation system that could act both as a recommendation system and as a means of exploring new anime genres and titles. We have analyzed the general trends in this field and the users' watching habits for coming up with our efficacious solution. Our solution employs deep autoencoders for the tasks of predicting ratings and generating embeddings. Following this, we formed clusters using the embeddings of the anime titles. These clusters form the search space for anime with similarities and are used to find anime similar to the ones liked and disliked by the user. This method, combined with the predicted ratings, forms the novel hybrid filter. In this article, we have demonstrated this idea and compared the performance of our implemented model with the existing state-of-the-art techniques.
翻译:Anime今天非常受欢迎, 特别是在年轻一代中。 有了众多的节目, 越来越多的人越来越被娱乐业的这个特殊部门吸引。 作为最近的主流关注, 我们对于用户的爱好和观赏习惯的信息不足。 因此, 为这个相对模糊的娱乐媒介建立一个建议引擎是一项艰巨的任务。 我们为此尝试建立了一个新型混合建议系统, 既可以作为推荐系统, 也可以作为探索新动因和标题的手段。 我们已经分析了这个领域的总体趋势, 以及用户在看如何利用我们的有效解决方案的习惯。 我们的解决方案在预测评级和生成嵌入功能的任务中使用了深度的自动编码。 在此之后, 我们利用蚂蚁名称的嵌入组成了群群。 这些群组成了与用户喜欢和不喜欢的元素的搜索空间, 并用来寻找与用户喜欢和不喜欢的元素相似的元素。 这个方法, 与预测的评级相结合, 形成了新的混合过滤器。 在文章中, 我们展示了这一想法, 并比较了我们所执行的状态的功能。