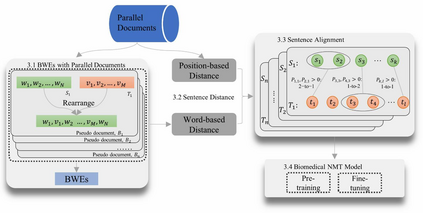
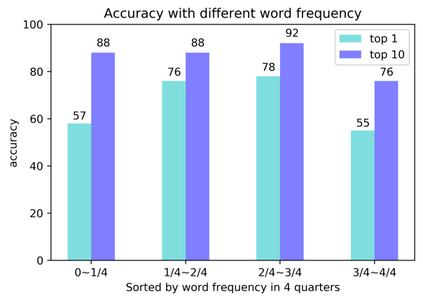
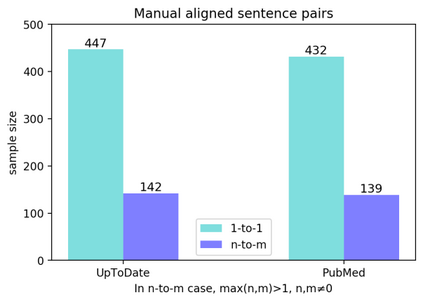
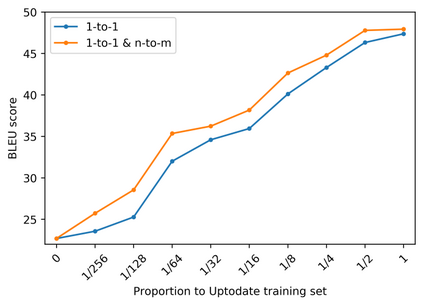
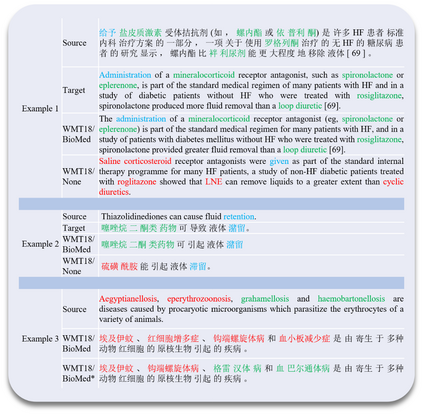
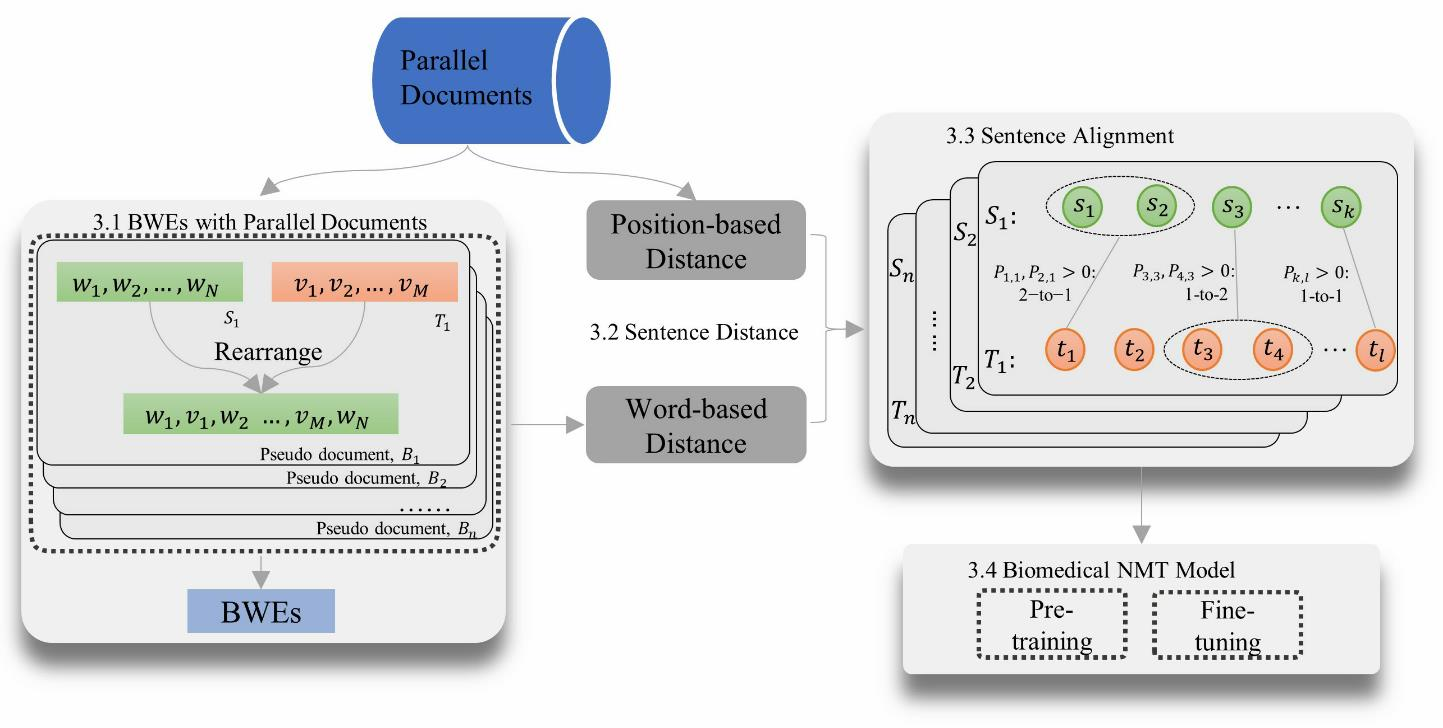
Objective: Today's neural machine translation (NMT) can achieve near human-level translation quality and greatly facilitates international communications, but the lack of parallel corpora poses a key problem to the development of translation systems for highly specialized domains, such as biomedicine. This work presents an unsupervised algorithm for deriving parallel corpora from document-level translations by using sentence alignment and explores how training materials affect the performance of biomedical NMT systems. Materials and Methods: Document-level translations are mixed to train bilingual word embeddings (BWEs) for the evaluation of cross-lingual word similarity, and sentence distance is defined by combining semantic and positional similarities of the sentences. The alignment of sentences is formulated as an extended earth mover's distance problem. A Chinese-English biomedical parallel corpus is derived with the proposed algorithm using bilingual articles from UpToDate and translations of PubMed abstracts, which is then used for the training and evaluation of NMT. Results: On two manually aligned translation datasets, the proposed algorithm achieved accurate sentence alignment in the 1-to-1 cases and outperformed competing algorithms in the many-to-many cases. The NMT model fine-tuned on biomedical data significantly improved the in-domain translation quality (zh-en: +17.72 BLEU; en-zh: +17.02 BLEU). Both the size of the training data and the combination of different corpora can significantly affect the model's performance. Conclusion: The proposed algorithm relaxes the assumption for sentence alignment and effectively generates accurate translation pairs that facilitate training high quality biomedical NMT models.
翻译:目标:今天的神经机器翻译(NMT)可以达到接近人文水平的翻译质量,并大大便利国际通信,但缺乏平行的连体对生物医学等高度专业化领域的翻译系统的发展构成一个关键问题。这项工作提供了一种未经监督的算法,通过使用句子校正,从文件级翻译中得出平行的连体体,并探索培训材料如何影响生物医学NMT系统的业绩。材料和方法:文件级翻译混合在一起,用于培训双语词嵌入(BWES),用于评价跨语言词相似性,而判决距离则通过将判决的语义和位置相似性结合起来来界定。判决的对等配对是一个关键问题。判决的配对是一个延长的地球移动者距离问题。中文-英语生物医学平行体与拟议使用双语文章从UpToate和PubMed摘要进行算法计算,然后用于培训和评估NMT。结果:在手动翻译数据集校准的数据集集中,拟议的算法在1-1个案例中实现了准确的句调,并在许多MDUB+MIT数据模型的翻译中大大超越了标准。