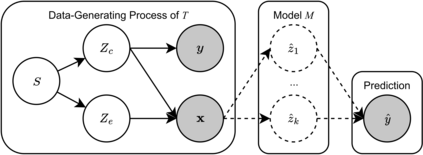
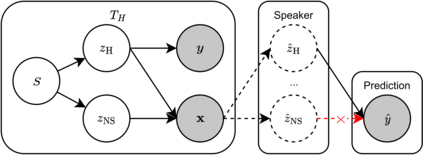
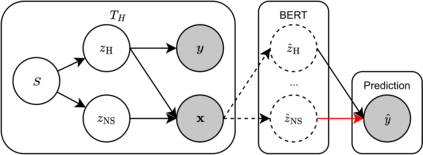
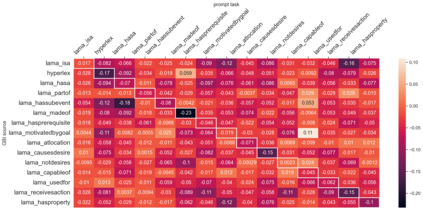
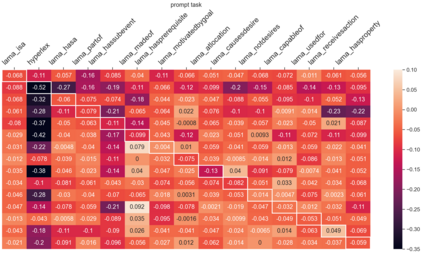
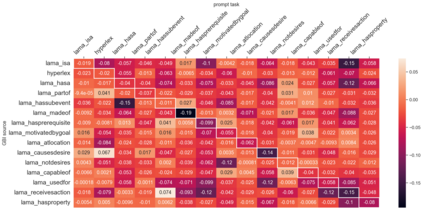
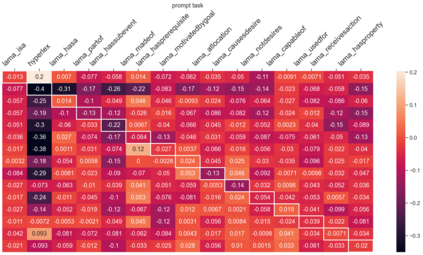
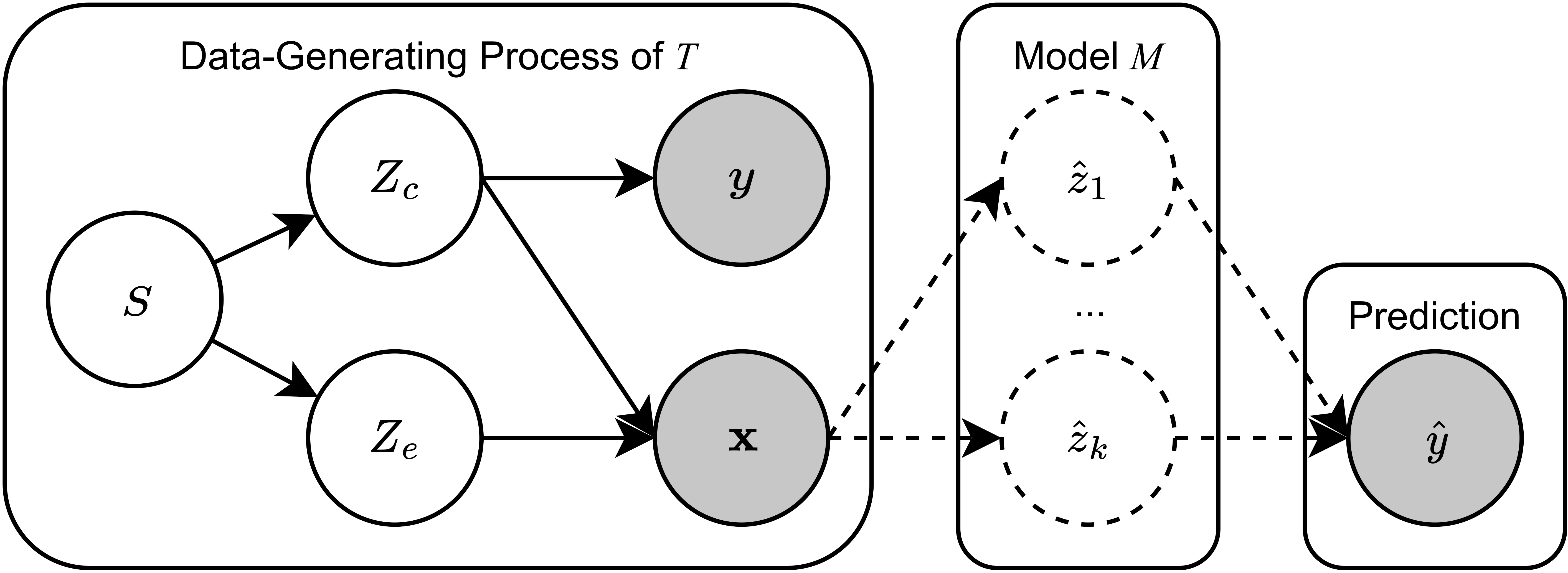
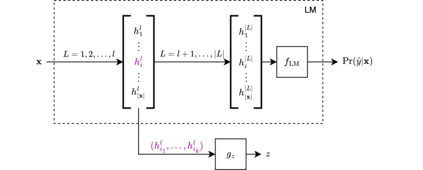Despite the recent success of large pretrained language models (LMs) on a variety of prompting tasks, these models can be alarmingly brittle to small changes in inputs or application contexts. To better understand such behavior and motivate the design of more robust LMs, we propose a general experimental framework, CALM (Competence-based Analysis of Language Models), where targeted causal interventions are utilized to damage an LM's internal representation of various linguistic properties in order to evaluate its use of each representation in performing a given task. We implement these interventions as gradient-based adversarial attacks, which (in contrast to prior causal probing methodologies) are able to target arbitrarily-encoded representations of relational properties, and carry out a case study of this approach to analyze how BERT-like LMs use representations of several relational properties in performing associated relation prompting tasks. We find that, while the representations LMs leverage in performing each task are highly entangled, they may be meaningfully interpreted in terms of the tasks where they are most utilized; and more broadly, that CALM enables an expanded scope of inquiry in LM analysis that may be useful in predicting and explaining weaknesses of existing LMs.
翻译:暂无翻译