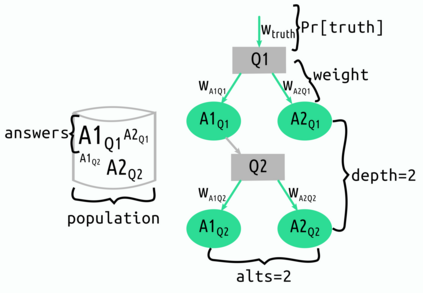
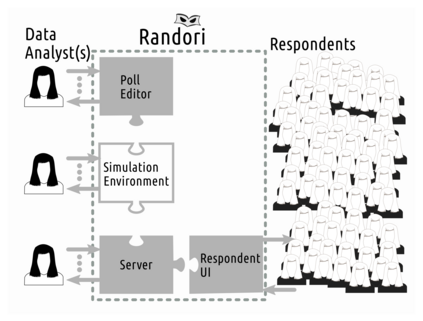
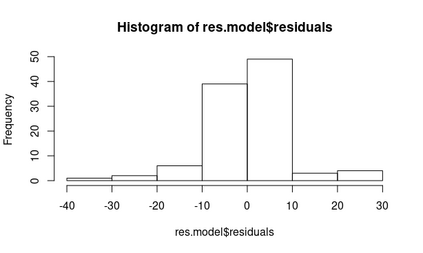
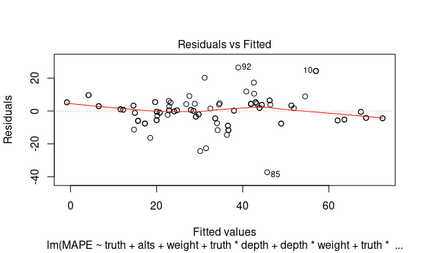
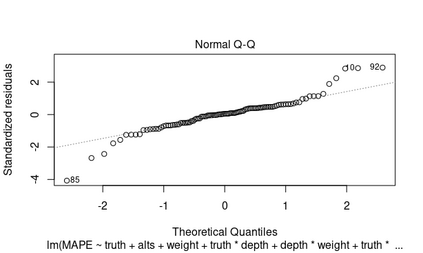
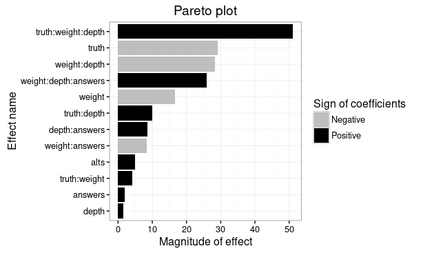
Differential privacy is a strong mathematical notion of privacy. Still, a prominent challenge when using differential privacy in real data collection is understanding and counteracting the accuracy loss that differential privacy imposes. As such, the accuracy-privacy trade-off of differential privacy needs to be balanced on a case-by-case basis. Applications in the literature tend to focus solely on analytical accuracy bounds, not include data in error prediction, or use arbitrary settings to measure error empirically. To fill the gap in the literature, we propose a novel application of factor experiments to create data aware error predictions. Basically, factor experiments provide a systematic approach to conducting empirical experiments. To demonstrate our methodology in action, we conduct a case study where error is dependent on arbitrarily complex tree structures. We first construct a tool to simulate poll data. Next, we use our simulated data to construct a least squares model to predict error. Last, we show how to validate the model. Consequently, our contribution is a method for constructing error prediction models that are data aware.
翻译:隐私差异是一个很强的数学隐私概念。然而,在实际数据收集中使用不同的隐私时,一个突出的挑战是理解和抵制差异隐私带来的准确性损失。因此,差异隐私的准确性-隐私权衡需要逐案平衡。文献的应用往往只侧重于分析准确性界限,不包括错误预测中的数据,或使用任意设置来测量错误。为了填补文献中的空白,我们提议对要素实验进行新的应用,以生成有数据意识的错误预测。基本上,要素实验为进行实验提供了系统的方法。为了展示我们的行动方法,我们进行了一个错误取决于任意复杂的树结构的案例研究。我们首先构建了一个模拟民意数据的工具。接下来,我们使用模拟数据来构建一个最小的方形模型来预测错误。最后,我们展示了如何验证模型。因此,我们的贡献是一种构建有数据意识的错误预测模型的方法。